I don’t know if this post is a rage against “database-ubiquitous” SQL or Object-Relational Mapping tools (ORMs)
I’m going to say that it’s a rant against the first because if you know what you are doing, then ORMs won’t be a performance concern
But people use ORMs instead of Stored Procedures because Them: “what happens if we need to change databases? We don’t have to worry about that now cause they’ll be baked in the application, and we won’t have to recreate the Stored Procedures in the new database cause ORMs just work!”
Everything just works until it doesn’t
I’ve worked with several companies and heard this argument many times from developers
Part of why I’m ranting about database-ubiquitousness SQL instead of ORMs is that I’ve also witnessed SQL code that has to work everywhere
I’m going to call this SQL “DUh SQL” from now on since I only have so many vowels on my keyboard and shouldn’t waste them re-writing the word “ubiquitousness”
Them: “Nope, we can’t use DATEFROMPARTS; it’s not available in other databases! Yeah, we use GETDATE() everywhere; what’s your point? WHAT!?!”
I’ve moved across different cloud providers more than I’ve moved databases, and guess what? Each cloud provider move, we’ve kept the same database
I know that knowledge sharing “in the wild” says that you should use ORMs or DUh SQL The route to a 10x engineer is paved in DRY, KISS, and SWALK Well, maybe not SWALK
Them: “But the leading minds out there say that you should keep it DUh since that means it’ll be a breeze if we have to move databases”
Sure, and I’ve been told that ice baths help in recovery I’m not going to take them, though, since I know there’s a difference between me trying to do a 5k and dedicated athletes!
I love arguing with people in my blog posts; I rarely lose
So, don’t use DUh SQL cause of reasons that may not apply to you Don’t refuse performance tuning efforts if they’ll add database-specific code And, please, learn to use your tools
Oh, and apologies for the lack of full-stops, I can’t use them in case I have to turn this post into regex
I recently ran into a problem with the QUOTED_IDENTIFIERS option in SQL Server, and it got me to thinking about these SET options.
I mean the fact that, on tables where there are filtered indexes or computed columns with indexes, QUOTED_IDENTIFIER is required to be on to create any other indexes is just not intuitive. But if you can’t create indexes because of it then I’d argue that it’s pretty damn important! I also found out that this problem is not just limited to QUOTED_IDENTIFIER but to ARITHABORT and ANSI_WARNINGS as well.
SET ARITHABORT must be ON when you are creating or changing indexes on computed columns or indexed views. If SET ARITHABORT is OFF, CREATE, UPDATE, INSERT, and DELETE statements on tables with indexes on computed columns or indexed views will fail.
And for ANSI_WARNINGS it says:
SET ANSI_WARNINGS must be ON when you are creating or manipulating indexes on computed columns or indexed views. If SET ANSI_WARNINGS is OFF, CREATE, UPDATE, INSERT, and DELETE statements on tables with indexes on computed columns or indexed views will fail.
It’s not just Indexes
So, like a dog when it sees a squirrel, when I found out about the problems with ARITHABORT and ANSI_WARNINGS I got distracted and started checking out what else I could break with it. Reading through the docs, because I found that it does help even if I have to force myself to do it sometimes, I found a little gem that I wanted to try and replicate. So here’s a reason why you should care about setting ARITHABORT and ANSI_WARNINGS on.
Default to on
At one stage or another if you’re working with SQL Server, you’ve probably encountered the dreaded “Divide By 0” error:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
If you want to check this out, then here’s the code below for our table:
USE Pantheon;
-- Create our test table...
CREATE TABLE dbo.ArithAborting (
id tinyint NULL
);
GO
And our attempt at inserting that value into the table:
SET ARITHABORT ON;
GO
SET ANSI_WARNINGS ON;
GO
-- Check can we insert a "divide by 0"...
BEGIN TRY
INSERT INTO dbo.ArithAborting (id) SELECT 1/0;
END TRY
BEGIN CATCH
PRINT 'NOPE!';
THROW;
END CATCH;
And we get our good, old, dreaded friend:
Terminate!
We check our ArithAborting table and nothing is there, like we expected!
SELECT *
FROM dbo.ArithAborting;
I got nothing…
What about if we were to turn our ARITHABORT and ANSI_WARNINGS off though, what happens then? Well that’s a simple thing to test, we just turn them off and run the script again:
--Turn ARITHABORT off;
SET ARITHABORT OFF;
GO
SET ANSI_WARNINGS OFF;
GO
-- ...insert into our table...
BEGIN TRY
INSERT INTO dbo.ArithAborting (id) SELECT 1/0;
END TRY
BEGIN CATCH
PRINT 'NOPE!';
THROW;
END CATCH;
Termin-wait…
Now before I freak out and start thinking that I’ve finally divided by zero, let’s check the table:
During expression evaluation when SET ARITHABORT is OFF, if an INSERT, DELETE or UPDATE statement encounters an arithmetic error, overflow, divide-by-zero, or a domain error, SQL Server inserts or updates a NULL value. If the target column is not nullable, the insert or update action fails and the user receives an error.
Do I like this?
Nope!
If I have a terminating error in my script, I quite like the fact that SQL Server is looking out for me and won’t let me put in bad data, but if you have these options turned off, even if you wrap your code in an TRY...CATCH block, it’s going to bypass it.
Plus if you are trying to divide by 0, please stop trying to break the universe. Thank you.
SQL New Blogger:
Time to investigate: 10 mins
Time to test: 10 mins
Time to write: 10 mins
While creating a script for some new tables I came across a few columns that were designated to have both CHECK constraints and DEFAULT constraints.
Now this isn’t a problem of itself, it can be easily achieved by using a CREATE TABLE statement and then using 2 ALTER TABLE statements to create the constraints.
Old Style:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The problem that I had with this was that, so far, I was going along and creating these tables & columns with the constraints created in-line and it just galled me to have to break this flow and create these constraints as ALTER statements.
Checking the examples in the new Microsoft Docs didn’t show any examples that I could find of creating both constraints together on the same column so I experimented and found out that you can!
Here’s how…
New Style:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
There is no need to specify a FOR <column name> on the default constraint because SQL Server can tell the constraint is to work on the column it is currently defining.
There is no comma separating the two constraints. This would break the inline property of these statements and SQL Server would think you’ve messed up syntax on a constraint (this got me for a sec).
Great, I can keep my constraints inline!
That’s a wrap
Documentation is useful but they do not cover every situation. Have a test environment; Hypothesize, test, and verify. You never know what you’d find.
A lot of the time, DBAs are asked to run adhoc reports for various business people and, more often than not, the expected medium for these reports is Excel.
Now for the most part this seems simple enough…
Run the T-SQL report
Highlight the results
Copy the results
Paste into an Excel worksheet
Simples!…right?
How do you deal with carriage returns though? New line feeds? Tabs? Commas when you’re trying to comma delimit?
Try and copy them into an Excel worksheet and what you’re going to get is confusion, alarm, and vexation.
Not exactly the clear reporting that the business people are hoping for.
So what can we do? Panic? Grab another coffee? Roll your “r’s”?
Yes, yes, and not yet…
Karaoke…
I have mentioned before that we can use CHAR(10) and CHAR(13) for new lines and carriage returns in SQL Server so I’ll leave it up to an exercise to the reader to create a table with these “troublesome” bits of information in them (plus if you came here from Google, I assume you already have a table with them in it).
For me, I’ve just created a single table dbo.NewLineNotes that has a single entry with a new line in it.
SQL Server is left, Report is right
So a straight-up copy and paste isn’t going to cut it here. If we have more than 1 row, we’re not going to get a 1 entry to 1 row in the report that we are looking for. How do people deal with this?
Let’s proceed with the impression that you do not have RedGate tools (coughfree trialcough) and cannot avail of the right-click righteousness, what do you do then.
Well…have you thought about PowerShell?
Hear me out on this but you probably already have your query but found the new lines are screwing up the report. So let’s throw that query into a variable
$NewLineQuery = 'SELECT Notes FROM dbo.NewLineNotes'
Then what we have to do is somehow connect to the SQL Server instance and database.
Let’s go with the very basics here as that’s all we really need. Invoke-SqlCmd, and yes I know it has problems. I’ve linked and talked about them before. It works for us in this situation though.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Now the more code-centered readers among you may have spotted and asked why I used -ExpandProperty and not just -Property , or even why I included it at all.
Well, apart from the thought that code online should be like code in scripts (legible with no aliases), we’re dealing with new lines here!
If we don’t specify -expand then what we actually get is…
comma delimited or ellipses delimited?
How does that help us with Reports?
If you work with PowerShell for the smallest amount of time, then I hope you’ve run into the command Export-CSV. See help for details…
help Export-Csv -Full
This will output a delimited file (defaults to comma but we can change that if we want) to wherever we want. We can then open it up in Excel or whatever other tool you use.
Let’s see if that splits our information into a new line!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
I make no effort to hide the fact that I am not the biggest fan of GUIs, and I’ve been fortunate enough to turn that dislike into an admiration of command line tools. I said “an admiration” not that I’m any good at them yet! I have been fortunate enough to provide a function for dbatools.io (have you helped them out yet?) but just goes to show that anyone can help out, regardless of skill level.
In case you ever wondered where this dislike came from, let me tell you a hypothetical story about…my friend that I used to work with.
Now my friend wasn’t a DBA then, he wasn’t even an Accidental DBA, he was more a “that guy is good with databases, ask him” kind of guy. In short, my friend knew just enough to be dangerous without knowing that he could be.
Back in the SQL Server 2012 days…
…which was either today or 5 years ago, depending on what version of SQL Server you’re running but we’ll say 5 years ago, my friend was working as a SQL Support Engineer for a software provider.
The provider didn’t handle backups, that was all taken care of by 3rd parties. In case something went wrong, these 3rd parties provided the backups and either the software provider, or the in-house I.T. would restore them. (FYI, I’m very cautious of 3rd party backup tools as well).
One Friday, we did a release…
…and eventually a bug was discovered in the release that could have potentially had some data impact (no particular reason to say Friday, I just don’t think you should release on one).
So a plan was made to request a 2 week old backup and to compare the current data against the current production database.
GUI Time…
My friend goes to the Object Explorer, opens the “Databases” node, and sees that there is two databases there; Live ([TheEarlyBird]) and a disused copy of Live ([TheEarlyBird2]) that is a day old and can be overwritten.
Not knowing any better, my friend right-clicks the old copy, clicks “Tasks”, then “Restore”, then “Database…”, and a lovely GUI pops up.
Now my friend doesn’t know any better, he thinks that the GUI is here to help him and in most of the cases it is. What my friend failed to realize is that there is a difference between helping him and doing the work for him…
Setting Up…
The 3rd party backup file has not yet been retrieved but that stops my friend not! This is a urgent case so my friend forges ahead, thinking that he can get everything set up and ready then all he would have to do is select the file when it was made available.
Files Page:
My friend would be overwriting the disused database so this would not need to be changed.
Options Page:
Checked the box “Overwrite the existing database (WITH REPLACE)” as we are overwriting the disused database
File is now available…
So my friend goes back to the General Page, clicks the “Device” radio button, and selects the backup file…
Can you figure out what went wrong here?
…and clicks “OK” to start the restore!
Errors! Errors galore…
My friend encounters errors:
Exclusive access could not be obtained because the database is in use.
This confuses my friend as this is a disused copy of the database, the only person who should be on it is himself.
Does my friend go and maybe check out EXEC sp_Who2; to see who else could be on this database? No, remember that my friend knows just enough to be dangerous. My friend goes back to “Tasks”, “Restores”, “Databases”, goes to the Options Page and checks the box labelled “Close existing connections to destination database”….
If you figured out the above, you know that this is even worse…
With that, my friend clicks the “OK” to restore the database and continues on his merry way…the dumb fool that he is.
SQL Server 2012 GUIs…
…have this little “optimization” technique where it looks at the name on the database backup file and matches up with the database name.
Now what this actually meant was the moment that my friend clicked the “Device” button, all his work was gone and his destination database reverted to the Live Database!
The first time my friend clicked “OK” to restore wasn’t a problem since there were connections and the Live database wasn’t affected.
But then my friend goes back and clicks “Close existing connections to destination database”…just enough knowledge to be dangerous…
So in summary, what my friend had done was kick every single connection off of Live and then effectively wiped 2 weeks worth of data.
Thank goodness for tail-log backups!
GUIs are good for….
…discovery.
They give you the option to script out the configurations you have chosen. If my friend had chosen to script out the restore, rather then clicking “OK” to run it, maybe he would have caught this mistake when reviewing it – rather than overwriting the Live database with 2 week old data and spending a weekend in the office with 3 colleagues fixing it.
I guess it’s a personal experience but I say that it is thanks to “my friend” that I was able to do 2 side-by-side WITH STOPAT database restores today.
If this was a horror movie, it would be called “The Differencing”…duh duh duh!
Time to read: ~ 5 minutes
Words: 1057
Update 2021-07-14: Marked code blocks as preformatted
The original post for this topic garnered the attention of a commenter who pointed out that the same result could be gathered using a couple of UNION ALLs and those lovely set-based EXCEPT and INTERSECT keywords.
I personally think that both options work and whatever you feel comfortable with, use that.
It did play on my mind though of what the performance differences would be…what would the difference in STATISTICS IO, TIME be? What would the difference in Execution Plans be? Would there even be any difference between the two or are they the same thing? How come it’s always the things I tell myself not to forget that I end up forgetting?
I have no idea about the last one but at least the other things we can check. I did mention to the commentor that I would find this an interesting blog topic if they wanted to give it a go and get back to me. All I can say is – Sorry, your mail must have got lost in transit. I’m sure it is a better blog post that mine anyway.
If you’re going to do it…
For this test, we’re not going to stop at a measely 4 columns per table. Oh no! For this one we’re going to go as wide as we can.
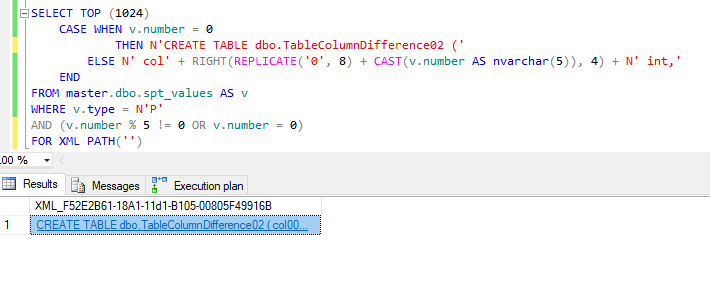
With a recent post by Kenneth Fisher ( blog | twitter ) out about T-SQL FizzBuzz, I’m going to create two tables, both of which will have incrementing column names i.e. col00001, col00002, …, col1024. Table1 will have all columns divisible by 3 removed while Table2 will have all columns divisible by 5 removed.
See, FizzBuzz can be useful!
So our table creation scripts…
SELECT TOP (1024) CASE WHEN v.number = 0 -- Change this to 02 the second run through THEN N'CREATE TABLE dbo.TableColumnDifference01 (' ELSE N' col' + RIGHT(REPLICATE('0', 8) + CAST(v.number AS nvarchar(5)), 4) + N' int,' END FROM master.dbo.spt_values AS v WHERE v.type = N'P' AND ( -- Change this to '% 5' the second run through v.number % 3 != 0 OR v.number = 0 ) FOR XML PATH('')
See Note
NOTE:When you copy and paste the results of this query into a new window to open it, it is going to fail. Why? Well the end of the script is going to be along the lines of colN int, and it needs to be colN int). Why is it like this? Well it was taking to damn long to script that out. Feel free to change this to work for you. Hey if you do, let me know!
Now, how I’m going to do test this, is run each method 3 times (PIVOT, UNION, and PowerShell), then measure the third run of each method. This is mainly as I want to get rid of any “cold cache” issues with SQL Server where the plan has to be compiled or the data brought into memory.
…do it Pivot
So first up is the Pivot method from the last blog post. In case you’re playing along at home (and go on, do! Why should kids get all the fun) here is the code that I’m running.
And here is our results:
Yup, those be columns
What we are really after though is the stats, execution plan and time to complete for our 3rd execution. Now as much as I love reading the messages tab for the stats information, I feel with blog posts that aesthetics is king, so I’m going to be using the free tool by Richie Rump ( twitter ) “Statistics Parser“
Stats:
Elapsed time: 00:00:00.136
Execution Plan:
Probably the first plan I’ve seen where the SORT isn’t the most expensive!
..do it UNION
Secondly we have what I dubbed “the UNION method” (no points for figuring out why) and the only change I’ve made to this script is to add in PARSENAME() and that’s only so that the script would..you know…work.
Yeah…so…that’s…that’s different from the first plan! I was right in my comment though, there is a concatenation operator (there’s actually 2, you may need to zoom in to find them though)
…do it PowerShell
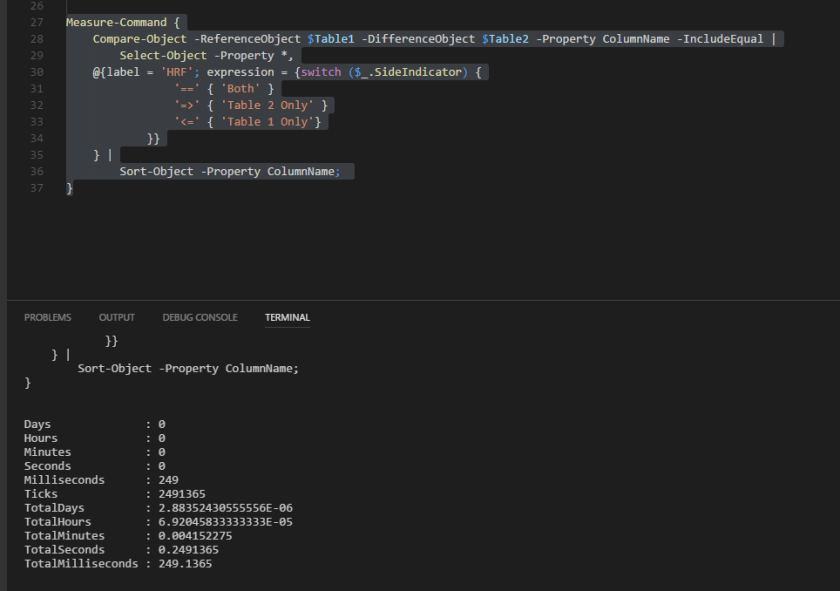
Finally we have the PowerShell method. No messing about here, let’s get straight to it! I’m going to lump all the code together in one gist and I’ll be wrapping it in Measure-Command to get the speed of the command.
Get-Results
Yeah I’m liking VS Code more and more…
Get-Stats:
Elapsed time: 00:00:00.249
help *execution*; help *plan*
Would you believe that I couldn’t figure out how to get an execution plan for PowerShell 🙂
If anybody knows, hit me up!
Finishing off
You know at the start of this, I was fully expecting the PowerShell to win out, followed by the UNION method, because it’s use of UNION, EXCEPT, and INTERSECT which are basically made for this kind of problem, and the PIVOT method bringing up a distant last since PIVOTs have this complexity stigma attached to them and what is complex is normally slow.
From a sheer speed point of view, the actual results are:
Pivot
PowerShell
Union
Who knew!?
I don’t think this is the end of my use of PowerShell or Union operators though. I’m not going to replace all the stuff that I can with Pivots. For one I just think that PowerShell and the Union operators are just too cool!
I actually like this result for two reasons.
There are multiple way to do something in SQL, there are good ways and better ways. The main point is whatever option you choose, make sure you know what it entails and can justify it. Whatever works for you, works for you!
You don’t know something, test it and find out! What you think the outcome may be, may not be true.
Now if you’ll excuse me, I want to figure out if there’s a way to return execution plans with PowerShell.
Straight away I want to apologise for the Nicolas Cage memes!
User Groups are great, aren’t they?
I just got back from the Reading User Group and I’m still in that post “User Group Glow”, also known as “Long Day Lethargy”, or “Twelve Hour Tiredness”.
They are great though! A chance to talk to other people in the SQL Server community, – a slight reminder that even if you work alone, people are still experiencing some of the same problems that you are (apparently everyone has to deal with multiple nested views, who knew!) – a chance to hear presentations on different topics, and pizza if you’re lucky (we were).
They’re really great!
I realised during the session that the two presentations given during the User Group had a connection with a small issue with a table change I had been given with a developer.
Here’s what did not happen to me so you can watch out for it.
The Chaos Theory
Nic Chaos
Raul Gonzalez ( blog | twitter ) was first up with this presentation “Database Design Matters, Seriously”, showing us the chaos that can occur from not giving some serious thought into how you design your database.
His session is not yet up on his blog as I’m writing this but it will be soon so keep an eye out for that!
Now he had a lot of good points but, for brevity’s sake, the main chaos theory points here are what happens if you don’t take advantage of CHECK CONSTRAINTS, FOREIGN KEY CONSTRAINTS, and not specifying a columns NULLABILITY (yes, that’s a word!). SQL Server is a powerful program with many performance optimizations provided for you, but it’s not omniscient; it can only use the information that you give it!
His points on NULLABILITY (I mean, I think it’s a word) tied in nicely with the next presentation…
Compound Effects
Compound Effects
David Morrison ( blog | twitter ) followed up with his presentation on “Query Plan Deep Dives” (I had seen this at SQL Bits, but it’s a great session so I had no problems watching it again) and, as an aside, through his presentation he showed us the compound effects that can happen from not specifying a columns NULLABILITY (it’s got letters so it’s word-like…)
Now his slides and scripts are up on his blog and they do a great job of walking you through them so check them out and you’ll see the compound effects they create!
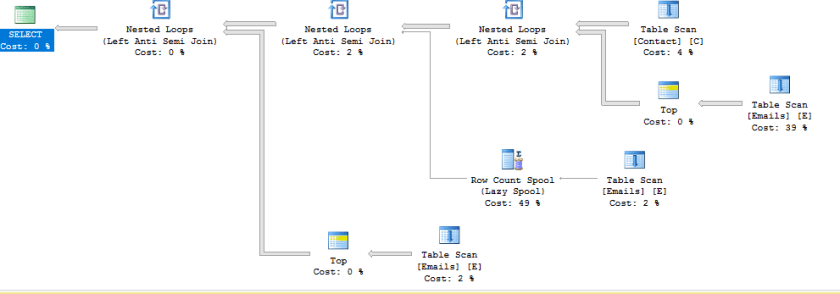
Here’s a little teaser…
-- now I want all people who's email isn't in the email table
SELECT /*C.FirstName ,
C.LastName ,*/
C.EmailAddress
FROM dbo.Contact AS C
WHERE C.EmailAddress NOT IN (SELECT E.EmailAddress
FROM dbo.Emails AS E)
GO
This should be A LOT simpler!!!
Consequences
Which brings us back around to consequences or as I like to put it “How I Pissed Off A Dev By Refusing A Simple Request”.
To be quite honest, it was a simple request. A requirement came in to expand a column datatype up to varchar(100), so one of devs wrote up a simple script and passed it onto the DBAs to check as part of the change control procedure.
ALTER TABLE tablename
ALTER COLUMN columnname varchar(100)
And I said no.
“WHY???!!!“, you may shout at me (he certainly did), but I’m going to say to you what I said to him. “Give me a chance to explain before you take my head off, alright?”
Argue with a DBA, go on!
While there is nothing wrong with the above code syntactically (is that a word?) but I couldn’t approve it since that column was originally NOT NULL and the above script would have stripped the column of that attribute! Business requirements dictated that it should not allow NULLS, and hey, who are we to argue with that 😐
Double checking to see if the column is NULL or NOT NULL allowed me to see a problem with that code, one that many people would consider simple enough to just allow it through at a quick glance. Which could have opened up problems further down the line if it had run…
Thanks to the User Group, I now know that it could have a knock on effect with our query plans as well!
ALTER TABLE tablename
ALTER COLUMN columnname varchar(100) NOT NULL
There, that’s better!
DBAs deal with databases and consequences
DBAs get a lot of stick sometime, the “Default Blame Acceptors” or the “Don’t Bother Asking” but a lot of the time, it’s not that we want to say no, it’s just that we have to take into consideration a thousand little things that could snowball into 1 giant problem.
“Not this second, let me check it out and see what we can do”
If pressed further, we may rely on the good, old “it depends” though. Hey, clichés are there for a reason; they work!
It just goes to show that, like the IT profession, DBAs are constantly evolving.
Continuosly learning, checking out new helping technologies, and going to User Groups are going to help us to deal with it.
Just remember, in the end,
P.S. I should probably mention that the Nicolas Cage memes are because of this blog post by Nate Johnson ( blog ) that I enjoyed so much that I had to do something in response. I’m not normally this crazy, I swear!
Ever created an XML Schema collection before? Our developers work with a lot of XML so I wasn’t surprised when eventually a request came in about permissions with XML SCHEMA COLLECTION.
Surprised that they had a permissions issue, yes, but not surprised that they were working with XML.
Why is it “an XML” and not “a XML”?
For information purposes, I’d normally provide a brief description of what an XML SCHEMA COLLECTION is but, being completely honest, I’m still not sure I can vocalize it in an understandable way. It’s kind of like explaining the colour purple without using other colours (and yes, that’s colour with a ‘u’).
I know what it is, I just can’t explain it properly…yet
So what I’m going to do is point you to the link for Microsoft docs for XML Schema Collection (done) and just gloss right over it (nothing to see here).
Permissions Shane, you mentioned permissions.
Right, sorry.
Investigation first. This was on the Development server and they had emailed me the creation code along with the error message they had received, which was this guy:
CREATE XML SCHEMA COLLECTION name AS
N'RANDOM XML ALERT...'
Msg 2797, Level 16, State 2, Line 20
The default schema does not exist.
However, when I ran the code, I got a different error message, mainly this guy:
CREATE XML SCHEMA COLLECTION name AS
N'RANDOM XML ALERT...'
Msg 9459, Level 16, State 1, Line 3
XML parsing: line 2, character 34, undeclared prefix
Which meant I had to go back and tell them to fix their darn XML.
Now I’m pretty sure we have a problems though:
That error message did not fill me with confidence. Yeah, sure they had bad XML but I was now fairly sure that there was also a permissions problem. Mainly because if there’s one thing that I’ve learned so far, it’s this:
No good can come from two different people getting two different errors from the same code!
Proper XML:
Proper XML was provided and ran by the developers but the same error message came back…
CREATE XML SCHEMA COLLECTION name AS
N'random xml alert...'
Msg 2797, Level 16, State 2, Line 20
The default schema does not exist.
The difference this time was, when I ran the code, I received the following message
Command(s) completed successfully.
…That’s not good.
Developers happy. DBAs not.
At this stage, I’m nearly convinced that it’s a permissions issue.
In my head I’m thinking of all the things that I can do to try and troubleshoot this problem.
Extended Events my session,
Ask my Senior DBA,
Cry
Then I realize that I’m jumping the gun again and I slow down, and check the first error message again. This time without the developers shouting in my ear, about permissions.
The DEFAULT schema
That says “schema”, not “permission”. Maybe the difference between the DBAs and the Devs was to do with default schema and not permissions this time. Let’s check it out!
SELECT
IIF(principal_id = 1, 'DBA', 'Dev') AS DBPrincipal,
default_schema_name
FROM sys.database_principals
WHERE principal_id IN (1, 14);
Devs don’t even have a default schema!
Wait, so it was a SCHEMA issue?
Have you checked the Examples section of Microsoft Docs? Normally, they are a great source of material for examples but if you check out the examples for XML Schema Collection , not one of them shows the schema name in the examples.
So, I walk over to the original developer and his machine, change his code to…
CREATE XML SCHEMA COLLECTION dbo.name_test AS
N'RANDOM XML ALERT...'
And it works!
Apparently what had happened was the Senior Dev had gotten sick of developers not specifying the schema when creating objects and had asked the Senior DBA to remove the default schema for Developers. That seems to work (by that I mean, everything error-ed out correctly), they were happy that developers now had to specify the schema, and life moved on.
Yet, later on, when the developer read the docs for XML Schema Collection, and saw that there was no schema in the examples, it didn’t cross their mind that a schema was required. So they didn’t specify it and that, in combination with no default schema, caused this whole mess.
The (fast food) takeaways:
Slow down! Don’t jump the gun,
Developers don’t know everything,
It’s not always permissions,
Schemas are important(!),
Having checklists for investigations are highly useful, and
Documentation, especially on past decisions, are even more useful!
Apologies for the blurb of a blog post but I have to go.
Apparently, there’s a permissions issue with a Stored Procedure now…
Where I compare scripts to BBQ because of course I would 😐
I have this personal opinion that one sign of a good DBA is their ability to automate things and, before the DBA world found PowerShell, the way to do this was with T-SQL.
For example, a T-SQL script to get permissions assigned to a database principal could also include a column to REVOKE those permissions. This could be “automated” with some dynamic SQL.
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
This can be improved A WHOLE LOT…
What about if we want to improve this?
This is nice but what about if we are paranoid forward-thinking enough to realize that this could cause us problems?
“How?” You ask. Well what happens if there existed another database, say [NeedsAllPermissions], with the same table name and the same login has permissions on it.
Are you going to revoke permissions from that database? It needs ALL of them! It says so in the name!
So in an effort to not shoot ourselves in the foot, we add in the database name to our revoke script.
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'USE '
+ DB_NAME()
+ 'GO'
+ N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
Yes, we’re only using our database now!
So all is well with the world…
Until the day comes when you actually want to revoke permissions to that user. So you run the above code, copy the RevokeMe column and paste it into the management window. and you get…
No GO my friend…
GO is a special little guy. It’s not exactly T-SQL. It’s a way of telling the SQL Server Management Studio (SSMS) to send everything before it, from the beginning of the script or the preceding GO, to the SQL Server instance.
A Transact-SQL statement cannot occupy the same line as a GO command. However, the line can contain comments.
GO is a special little snowflake and needs to be on his own line then. Simple enough if you know that SQL Server converts CHAR(10) into a New Line.
If you didn’t know that, well you know that now….P.S. CHAR(13) is a carriage return 😉
So let’s update our script with some CHAR(10) and see what happens then.
SQL & BBQ, both work well with CHAR
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'USE '
+ DB_NAME()
+ CHAR(10)
+ 'GO'
+ CHAR(10)
+ N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
That smokey, wood-fire CHAR
Now, when we paste the RevokeMe column to a new window, we get…
Oh look, it’s a wild, rare nothing…I love them!
…absolutely no difference. 🙂
Why am I smiling?
Here, around 500 words in, we get to the meat of our post. How do we keep new lines when copying in SQL Server?
Tools | Options | Query Results | Results to Grid | Retain CR/LF on copy or save
Two things need to be done here.
This checkbox needs to be enabled.
CHECK!
A new window needs to be opened and used.
New window open, we run our script again, and this time, when we copy and paste the results, we get…
Winner, Winner, BBQ Chicken Dinner
Dessert:
So if you are using T-SQL to create scripts, and you’re having this problem with GO or just new lines in general, make sure that the “retain CR/LF on copy and save” checkbox is ticked.
Now, improve that script more, throw it in a stored procedure, and you never know, it may be semi-useful. 🙂
I’m going to point people to this that have “My Group By isn’t working” questions…
The Joys of SQL:
Did you know that the SQL language allows you to do amazing analysis of data such as aggregate functions?
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id,
t.request_id;
0’s! Amazing!
The Pains of SQL:
But…if you forget to put in the GROUP BY clause, as a ski instructor once said, you’re going to have a bad time!
Pizza…French Fries…Pizza
The Repetitiveness of Questioners:
So some eager yet lost scholar ventures into this land of aggregate functions, reads the error message and adds in a GROUP BY clause.
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id;
Trawling the bulletin boards, question sites, and forums – okay maybe a quick question online, it’s called poetic exaggerationpeople! – they eventually learn the folly of their ways and correct their mistake.
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id,
t.request_id;
PIZZA!
The Euphoria of SQL Prompt:
Now I consider myself lucky that work has invested in the RedGate tools, and right now, especially SQL Prompt.
I’m not going to talk about “Save and Recover Lost Tabs” – saved my ass many times.
I’m not going to talk about “Code Formatting” – saved my sanity many times.
I’m going to talk about “Autocomplete”.
A well-known secret with SQL Prompt’s autocomplete is the snippets feature. With this, you can increase your productivity by 75% from typing out G R O U P [space] B Y and instead use gb and hit tab.
Wait? I can order Pizza?
The Ecstasy of SQL Prompt:
Do not get me wrong, a 75% increase in productivity? I’ll take that!
That is a well-known secret though, and it’s slightly hard to get excited about a well-known secret.
However, what if I told you that SQL Prompt had another lesser-known secret that can increase your productivity and ensure that you do not forgot to add the necessary columns to your GROUP BY clause?
Interested? Ah c’mon!
You sure you’re not interested?…. That’s better!
So first of all, let us increase the number of non-aggregated columns in our SELECT to include database_id, is_remote_work, and exec_context_id. Including our session_id and request_id these are all columns that we are going to need to add to our GROUP BY clause, because…well…business logic.
Only problem is ain’t nobody got time for that.
SQL Prompt knows this and adds the following little snippet after a GROUP BY autocomplete.
Whoa! Whoa! You can deliver Pizza to me?
Hitting tab on that includes everything in the SELECT that is not part of an aggregate function, leaving us to concern ourselves with loftier things…
Like whatever happened to Pizza in 30 mins or free?
Pizza:
Now I don’t work for pizza RedGate, I’m not affiliated with them, and I don’t get any money off of them. In fact, I’d say that they’d happily pay me not to write about them but when I found this autocomplete feature, I got too happy not to share it!
So save yourself the trouble of typing everything out and spare yourself the pain of error messages.
Use this lesser-known secret and have more time for pizza.