I recently ran into a problem with the QUOTED_IDENTIFIERS option in SQL Server, and it got me to thinking about these SET options.
I mean the fact that, on tables where there are filtered indexes or computed columns with indexes, QUOTED_IDENTIFIER is required to be on to create any other indexes is just not intuitive. But if you can’t create indexes because of it then I’d argue that it’s pretty damn important! I also found out that this problem is not just limited to QUOTED_IDENTIFIER but to ARITHABORT and ANSI_WARNINGS as well.
SET ARITHABORT must be ON when you are creating or changing indexes on computed columns or indexed views. If SET ARITHABORT is OFF, CREATE, UPDATE, INSERT, and DELETE statements on tables with indexes on computed columns or indexed views will fail.
And for ANSI_WARNINGS it says:
SET ANSI_WARNINGS must be ON when you are creating or manipulating indexes on computed columns or indexed views. If SET ANSI_WARNINGS is OFF, CREATE, UPDATE, INSERT, and DELETE statements on tables with indexes on computed columns or indexed views will fail.
It’s not just Indexes
So, like a dog when it sees a squirrel, when I found out about the problems with ARITHABORT and ANSI_WARNINGS I got distracted and started checking out what else I could break with it. Reading through the docs, because I found that it does help even if I have to force myself to do it sometimes, I found a little gem that I wanted to try and replicate. So here’s a reason why you should care about setting ARITHABORT and ANSI_WARNINGS on.
Default to on
At one stage or another if you’re working with SQL Server, you’ve probably encountered the dreaded “Divide By 0” error:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
If you want to check this out, then here’s the code below for our table:
USE Pantheon;
-- Create our test table...
CREATE TABLE dbo.ArithAborting (
id tinyint NULL
);
GO
And our attempt at inserting that value into the table:
SET ARITHABORT ON;
GO
SET ANSI_WARNINGS ON;
GO
-- Check can we insert a "divide by 0"...
BEGIN TRY
INSERT INTO dbo.ArithAborting (id) SELECT 1/0;
END TRY
BEGIN CATCH
PRINT 'NOPE!';
THROW;
END CATCH;
And we get our good, old, dreaded friend:
Terminate!
We check our ArithAborting table and nothing is there, like we expected!
SELECT *
FROM dbo.ArithAborting;
I got nothing…
What about if we were to turn our ARITHABORT and ANSI_WARNINGS off though, what happens then? Well that’s a simple thing to test, we just turn them off and run the script again:
--Turn ARITHABORT off;
SET ARITHABORT OFF;
GO
SET ANSI_WARNINGS OFF;
GO
-- ...insert into our table...
BEGIN TRY
INSERT INTO dbo.ArithAborting (id) SELECT 1/0;
END TRY
BEGIN CATCH
PRINT 'NOPE!';
THROW;
END CATCH;
Termin-wait…
Now before I freak out and start thinking that I’ve finally divided by zero, let’s check the table:
During expression evaluation when SET ARITHABORT is OFF, if an INSERT, DELETE or UPDATE statement encounters an arithmetic error, overflow, divide-by-zero, or a domain error, SQL Server inserts or updates a NULL value. If the target column is not nullable, the insert or update action fails and the user receives an error.
Do I like this?
Nope!
If I have a terminating error in my script, I quite like the fact that SQL Server is looking out for me and won’t let me put in bad data, but if you have these options turned off, even if you wrap your code in an TRY...CATCH block, it’s going to bypass it.
Plus if you are trying to divide by 0, please stop trying to break the universe. Thank you.
This is yet another time that a blog post has come about from a question by a developer. They’re good guys, I guess, they keep me on my toes.
This time it was with change logging. We didn’t have Change Data Capture (CDC), or Temporal Tables enabled (have you seen the YouTube videos by Bert Wagner ( blog | twitter ) on these?). What we did have was “manual logging” and no, I’m not even talking about Triggers.
What we had was INSERT statements, directly after a MERGE statement, that inserted into a table variable a hard-coded name of the column, the old value, and the new value.
Is that what I would do? Doesn’t matter, it was there before I got there, seems to work, and is low down on the list of priorities to change.
The question was, every time that they needed to add a column to a table, and change log it, they had to add multiple lines to the change tracking procedure and the procedure was getting gross and hard to maintain.
You know the drill by now, I quite like to play along so let us facilitate that (from now on I’m going to use Gist, formatting with native WordPress is starting to annoy me).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This will create our table and, luckily, all of it’s columns are important enough to warrant capturing when they get changed.
Despite their looks, these values are “important”
Old, Way WHERE old=way
Let’s take a look at the code that they were using, shall we?
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Hey! It’s legacy code, let’s focus on just 1 problem at at time!
The main issue that I was asked about was every time a column was deemed important and needed to be added to the list, they had to insert another INSERT INTO @ChangeLogTemp... and they thought that it wasn’t sustainable in the long run.
Hmmm it also comes across as very RBAR doesn’t it? Every time we want to include another column to the change tracking, we have to add them row by agonizing row. The script is already big enough, if we keep adding more, it will get massive!
Set based is 90% of the time the right way to go but how do we do set based solutions on the same table?
New JOIN Way ON new = way
The first thing I do is to change that table variable into a temp table. Stats, indexes (if necessary), and I can query the results as we go along. Much better!
Temp > Variable?
The second thing is that, whether by luck or by design, the legacy code has the same naming conventions for the columns; new column values are have the prefix “New%” in the column name and old columns have the “Old%” prefix.
This works for us because we can now split the new columns into 2 derived tables, New and Old, and that way we have the differences.
Potential problem here…
Have you ever tried to find the differences between two consecutive rows of data? It’s fiendishly difficult. WHERE Column1 on row1 != Column1 on row2 apparently just does not work, le sigh.
I’ve talked before about PIVOT but now I’m going to introduce you to it’s little brother, UNPIVOT, which “rotating columns of a table-valued expression into column values”
I say “little brother” because the whole document talks about PIVOT, with only brief mentions of UNPIVOT in the notes.
If you’re writing documentation like this, please stop.
With UNPIVOT we can create a table of our rows around our ID and Column names…
Potential problem averted!
… and with this, we can join on our ID and Column names and get to our more intuitive WHERE OldValue != NewValue.
Bringing it all together!
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
The whole thing was supposed to be to reduce the amount of changes required when they need to include or exclude columns. All in all though, it’s just 6 lines less. Not exactly the great return that you’d expect.
Yeah, true with the old way for every column we want to add we have to add an extra 6 lines while the new way adds 2.
That means for 1,024 columns:
The old way could have at least 6,144 lines per table. (1024 * 6)
The new way could have at least 2,048 lines per table (not explaining this calculation >:( )
So, is there anything else that we can do?
Dynamically?
I’ve talked before about T-SQL automation with Dynamic SQL and this should be a good candidate for that.
What can we make dynamic here though? How about…
The new and old columns bit?
The FOR ColumnName IN([Column1], [Column2], [Column3], [Column4], [Column5], [Column6]) bit?
The CAST(ISNULL([Old/NewColumn], '') AS nvarchar bit?
This is basically the same as the above. Don’t be put off by needing to add CAST(ISNULL( before the column names, it’s not as complex as you’d think.
STUFF just doesn’t look as pretty… 🙁
Now that we have our dynamic bits, let’s create the full statements.
Full Dynamic Script
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
N'SELECT New.ColumnName AS CN, New.NewValue AS NV, Old.OldValue AS OV FROM (SELECT Unpvt.GotAnyChangeId, Unpvt.ColumnName, Unpvt.NewValue FROM (SELECT [GotAnyChangeId], ' + @NewColumns
+ N' FROM #OutputTableDynamic ) AS DataSource UNPIVOT (NewValue FOR ColumnName IN (' + @columns
+ N') ) AS Unpvt ) AS New INNER JOIN ( SELECT Unpvt.GotAnyChangeId, Unpvt.ColumnName, Unpvt.OldValue FROM (SELECT [GotAnyChangeId], ' + @OldColumns
+ N' FROM #OutputTableDynamic ) AS DataSource UNPIVOT (OldValue FOR ColumnName IN (' + @columns
+ N')) AS Unpvt) AS Old ON Old.ColumnName = New.ColumnName AND Old.GotAnyChangeId = New.GotAnyChangeId WHERE New.NewValue != Old.OldValue FOR XML PATH(''Change''), ROOT(''Changes'')';
Overall, the script is longer at nearly double the lines but where it shines is when adding new columns.
To include new columns, just add them to the table; to exclude them, just add in a filter clause.
So, potentially, if every column in this table is to be tracked and we add columns all the way up to 1,024 columns, this code will not increase. Old way: at least 6,144. New way: at least 2,048. Dynamic: no change
Summary:
Like the script, this was a massive post. Back at the start, I said that a developer came to me because they wanted to get more DRY (?) and stop needing to add more content to the stored procedure.
Do you think the developer used this?
Nope!
I can’t say that I blame them, it’s slightly ugly and unwieldy, and I wrote it so I should love it.
Yet if something was to go wrong and the need was there to open the procedure and troubleshoot it, the first person to open this up is going to let out a groan of despair!
So this request turned into a proof of concept and nothing more. No skin off my back, I have a growing list of tasks to accomplish by 5 minutes ago. Better get back to them.
Straight away I want to apologise for the Nicolas Cage memes!
User Groups are great, aren’t they?
I just got back from the Reading User Group and I’m still in that post “User Group Glow”, also known as “Long Day Lethargy”, or “Twelve Hour Tiredness”.
They are great though! A chance to talk to other people in the SQL Server community, – a slight reminder that even if you work alone, people are still experiencing some of the same problems that you are (apparently everyone has to deal with multiple nested views, who knew!) – a chance to hear presentations on different topics, and pizza if you’re lucky (we were).
They’re really great!
I realised during the session that the two presentations given during the User Group had a connection with a small issue with a table change I had been given with a developer.
Here’s what did not happen to me so you can watch out for it.
The Chaos Theory
Nic Chaos
Raul Gonzalez ( blog | twitter ) was first up with this presentation “Database Design Matters, Seriously”, showing us the chaos that can occur from not giving some serious thought into how you design your database.
His session is not yet up on his blog as I’m writing this but it will be soon so keep an eye out for that!
Now he had a lot of good points but, for brevity’s sake, the main chaos theory points here are what happens if you don’t take advantage of CHECK CONSTRAINTS, FOREIGN KEY CONSTRAINTS, and not specifying a columns NULLABILITY (yes, that’s a word!). SQL Server is a powerful program with many performance optimizations provided for you, but it’s not omniscient; it can only use the information that you give it!
His points on NULLABILITY (I mean, I think it’s a word) tied in nicely with the next presentation…
Compound Effects
Compound Effects
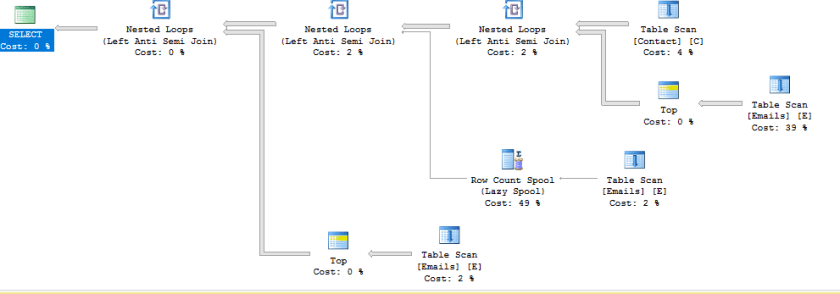
David Morrison ( blog | twitter ) followed up with his presentation on “Query Plan Deep Dives” (I had seen this at SQL Bits, but it’s a great session so I had no problems watching it again) and, as an aside, through his presentation he showed us the compound effects that can happen from not specifying a columns NULLABILITY (it’s got letters so it’s word-like…)
Now his slides and scripts are up on his blog and they do a great job of walking you through them so check them out and you’ll see the compound effects they create!
Here’s a little teaser…
-- now I want all people who's email isn't in the email table
SELECT /*C.FirstName ,
C.LastName ,*/
C.EmailAddress
FROM dbo.Contact AS C
WHERE C.EmailAddress NOT IN (SELECT E.EmailAddress
FROM dbo.Emails AS E)
GO
This should be A LOT simpler!!!
Consequences
Which brings us back around to consequences or as I like to put it “How I Pissed Off A Dev By Refusing A Simple Request”.
To be quite honest, it was a simple request. A requirement came in to expand a column datatype up to varchar(100), so one of devs wrote up a simple script and passed it onto the DBAs to check as part of the change control procedure.
ALTER TABLE tablename
ALTER COLUMN columnname varchar(100)
And I said no.
“WHY???!!!“, you may shout at me (he certainly did), but I’m going to say to you what I said to him. “Give me a chance to explain before you take my head off, alright?”
Argue with a DBA, go on!
While there is nothing wrong with the above code syntactically (is that a word?) but I couldn’t approve it since that column was originally NOT NULL and the above script would have stripped the column of that attribute! Business requirements dictated that it should not allow NULLS, and hey, who are we to argue with that 😐
Double checking to see if the column is NULL or NOT NULL allowed me to see a problem with that code, one that many people would consider simple enough to just allow it through at a quick glance. Which could have opened up problems further down the line if it had run…
Thanks to the User Group, I now know that it could have a knock on effect with our query plans as well!
ALTER TABLE tablename
ALTER COLUMN columnname varchar(100) NOT NULL
There, that’s better!
DBAs deal with databases and consequences
DBAs get a lot of stick sometime, the “Default Blame Acceptors” or the “Don’t Bother Asking” but a lot of the time, it’s not that we want to say no, it’s just that we have to take into consideration a thousand little things that could snowball into 1 giant problem.
“Not this second, let me check it out and see what we can do”
If pressed further, we may rely on the good, old “it depends” though. Hey, clichés are there for a reason; they work!
It just goes to show that, like the IT profession, DBAs are constantly evolving.
Continuosly learning, checking out new helping technologies, and going to User Groups are going to help us to deal with it.
Just remember, in the end,
P.S. I should probably mention that the Nicolas Cage memes are because of this blog post by Nate Johnson ( blog ) that I enjoyed so much that I had to do something in response. I’m not normally this crazy, I swear!
Where I compare scripts to BBQ because of course I would 😐
I have this personal opinion that one sign of a good DBA is their ability to automate things and, before the DBA world found PowerShell, the way to do this was with T-SQL.
For example, a T-SQL script to get permissions assigned to a database principal could also include a column to REVOKE those permissions. This could be “automated” with some dynamic SQL.
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
This can be improved A WHOLE LOT…
What about if we want to improve this?
This is nice but what about if we are paranoid forward-thinking enough to realize that this could cause us problems?
“How?” You ask. Well what happens if there existed another database, say [NeedsAllPermissions], with the same table name and the same login has permissions on it.
Are you going to revoke permissions from that database? It needs ALL of them! It says so in the name!
So in an effort to not shoot ourselves in the foot, we add in the database name to our revoke script.
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'USE '
+ DB_NAME()
+ 'GO'
+ N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
Yes, we’re only using our database now!
So all is well with the world…
Until the day comes when you actually want to revoke permissions to that user. So you run the above code, copy the RevokeMe column and paste it into the management window. and you get…
No GO my friend…
GO is a special little guy. It’s not exactly T-SQL. It’s a way of telling the SQL Server Management Studio (SSMS) to send everything before it, from the beginning of the script or the preceding GO, to the SQL Server instance.
A Transact-SQL statement cannot occupy the same line as a GO command. However, the line can contain comments.
GO is a special little snowflake and needs to be on his own line then. Simple enough if you know that SQL Server converts CHAR(10) into a New Line.
If you didn’t know that, well you know that now….P.S. CHAR(13) is a carriage return 😉
So let’s update our script with some CHAR(10) and see what happens then.
SQL & BBQ, both work well with CHAR
SELECT dprin.name AS DatabasePrincipalName,
OBJECT_NAME(dperm.major_id) AS ObjectName,
dperm.permission_name AS PermissionName,
N'USE '
+ DB_NAME()
+ CHAR(10)
+ 'GO'
+ CHAR(10)
+ N'REVOKE '
+ dperm.permission_name
+ N' ON OBJECT::'
+ OBJECT_NAME(dperm.major_id)
+ N' FROM '
+ dprin.name COLLATE Latin1_General_CI_AS AS RevokeMe
FROM sys.database_permissions AS dperm
INNER JOIN sys.database_principals AS dprin
ON dperm.grantee_principal_id = dprin.principal_id
WHERE dprin.name = 'public';
That smokey, wood-fire CHAR
Now, when we paste the RevokeMe column to a new window, we get…
Oh look, it’s a wild, rare nothing…I love them!
…absolutely no difference. 🙂
Why am I smiling?
Here, around 500 words in, we get to the meat of our post. How do we keep new lines when copying in SQL Server?
Tools | Options | Query Results | Results to Grid | Retain CR/LF on copy or save
Two things need to be done here.
This checkbox needs to be enabled.
CHECK!
A new window needs to be opened and used.
New window open, we run our script again, and this time, when we copy and paste the results, we get…
Winner, Winner, BBQ Chicken Dinner
Dessert:
So if you are using T-SQL to create scripts, and you’re having this problem with GO or just new lines in general, make sure that the “retain CR/LF on copy and save” checkbox is ticked.
Now, improve that script more, throw it in a stored procedure, and you never know, it may be semi-useful. 🙂