
User Groups are great, aren’t they?
I just got back from the Reading User Group and I’m still in that post “User Group Glow”, also known as “Long Day Lethargy”, or “Twelve Hour Tiredness”.
They are great though! A chance to talk to other people in the SQL Server community, – a slight reminder that even if you work alone, people are still experiencing some of the same problems that you are (apparently everyone has to deal with multiple nested views, who knew!) – a chance to hear presentations on different topics, and pizza if you’re lucky (we were).

I realised during the session that the two presentations given during the User Group had a connection with a small issue with a table change I had been given with a developer.
Here’s what did not happen to me so you can watch out for it.
The Chaos Theory

Raul Gonzalez ( blog | twitter ) was first up with this presentation “Database Design Matters, Seriously”, showing us the chaos that can occur from not giving some serious thought into how you design your database.
His session is not yet up on his blog as I’m writing this but it will be soon so keep an eye out for that!
Now he had a lot of good points but, for brevity’s sake, the main chaos theory points here are what happens if you don’t take advantage of CHECK CONSTRAINTS, FOREIGN KEY CONSTRAINTS, and not specifying a columns NULLABILITY (yes, that’s a word!). SQL Server is a powerful program with many performance optimizations provided for you, but it’s not omniscient; it can only use the information that you give it!
His points on NULLABILITY (I mean, I think it’s a word) tied in nicely with the next presentation…
Compound Effects

David Morrison ( blog | twitter ) followed up with his presentation on “Query Plan Deep Dives” (I had seen this at SQL Bits, but it’s a great session so I had no problems watching it again) and, as an aside, through his presentation he showed us the compound effects that can happen from not specifying a columns NULLABILITY (it’s got letters so it’s word-like…)
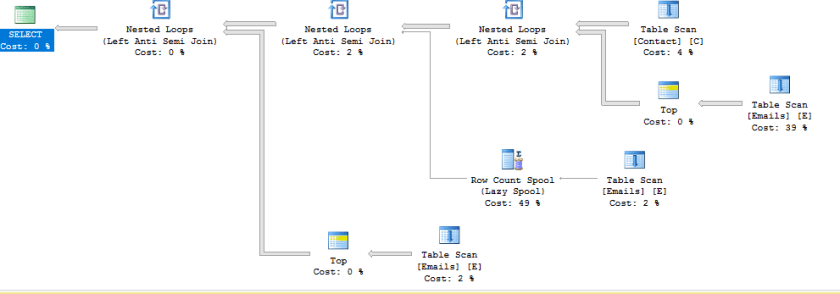
Now his slides and scripts are up on his blog and they do a great job of walking you through them so check them out and you’ll see the compound effects they create!
Here’s a little teaser…
-- now I want all people who's email isn't in the email table
SELECT /*C.FirstName ,
C.LastName ,*/
C.EmailAddress
FROM dbo.Contact AS C
WHERE C.EmailAddress NOT IN (SELECT E.EmailAddress
FROM dbo.Emails AS E)
GO
Consequences
Which brings us back around to consequences or as I like to put it “How I Pissed Off A Dev By Refusing A Simple Request”.
To be quite honest, it was a simple request. A requirement came in to expand a column datatype up to varchar(100), so one of devs wrote up a simple script and passed it onto the DBAs to check as part of the change control procedure.
ALTER TABLE tablename ALTER COLUMN columnname varchar(100)
And I said no.
“WHY???!!!“, you may shout at me (he certainly did), but I’m going to say to you what I said to him. “Give me a chance to explain before you take my head off, alright?”

While there is nothing wrong with the above code syntactically (is that a word?) but I couldn’t approve it since that column was originally NOT NULL and the above script would have stripped the column of that attribute! Business requirements dictated that it should not allow NULLS, and hey, who are we to argue with that 😐
Double checking to see if the column is NULL or NOT NULL allowed me to see a problem with that code, one that many people would consider simple enough to just allow it through at a quick glance. Which could have opened up problems further down the line if it had run…
Thanks to the User Group, I now know that it could have a knock on effect with our query plans as well!
ALTER TABLE tablename ALTER COLUMN columnname varchar(100) NOT NULL
There, that’s better!
DBAs deal with databases and consequences

DBAs get a lot of stick sometime, the “Default Blame Acceptors” or the “Don’t Bother Asking” but a lot of the time, it’s not that we want to say no, it’s just that we have to take into consideration a thousand little things that could snowball into 1 giant problem.
With the rise of DevOps, check out the latest T-SQL Tuesday, DBAs have gone from going
“No”
to somewhere along the lines of
“Not this second, let me check it out and see what we can do”
If pressed further, we may rely on the good, old “it depends” though. Hey, clichés are there for a reason; they work!
It just goes to show that, like the IT profession, DBAs are constantly evolving.
Continuosly learning, checking out new helping technologies, and going to User Groups are going to help us to deal with it.
Just remember, in the end,

P.S. I should probably mention that the Nicolas Cage memes are because of this blog post by Nate Johnson ( blog ) that I enjoyed so much that I had to do something in response. I’m not normally this crazy, I swear!








