
Time to read: ~ 5 minutes
Words: 1057
Update 2021-07-14: Marked code blocks as preformatted
The original post for this topic garnered the attention of a commenter who pointed out that the same result could be gathered using a couple of UNION ALLs and those lovely set-based EXCEPT and INTERSECT keywords.
I personally think that both options work and whatever you feel comfortable with, use that.
It did play on my mind though of what the performance differences would be…what would the difference in STATISTICS IO, TIME be? What would the difference in Execution Plans be? Would there even be any difference between the two or are they the same thing? How come it’s always the things I tell myself not to forget that I end up forgetting?
I have no idea about the last one but at least the other things we can check. I did mention to the commentor that I would find this an interesting blog topic if they wanted to give it a go and get back to me. All I can say is – Sorry, your mail must have got lost in transit. I’m sure it is a better blog post that mine anyway.
If you’re going to do it…
For this test, we’re not going to stop at a measely 4 columns per table. Oh no! For this one we’re going to go as wide as we can.
With a recent post by Kenneth Fisher ( blog | twitter ) out about T-SQL FizzBuzz, I’m going to create two tables, both of which will have incrementing column names i.e. col00001, col00002, …, col1024. Table1 will have all columns divisible by 3 removed while Table2 will have all columns divisible by 5 removed.
See, FizzBuzz can be useful!
So our table creation scripts…
SELECT TOP (1024)
CASE WHEN v.number = 0
-- Change this to 02 the second run through
THEN N'CREATE TABLE dbo.TableColumnDifference01 ('
ELSE N' col' + RIGHT(REPLICATE('0', 8) + CAST(v.number AS nvarchar(5)), 4) + N' int,'
END
FROM master.dbo.spt_values AS v
WHERE v.type = N'P'
AND (
-- Change this to '% 5' the second run through
v.number % 3 != 0
OR v.number = 0
)
FOR XML PATH('')
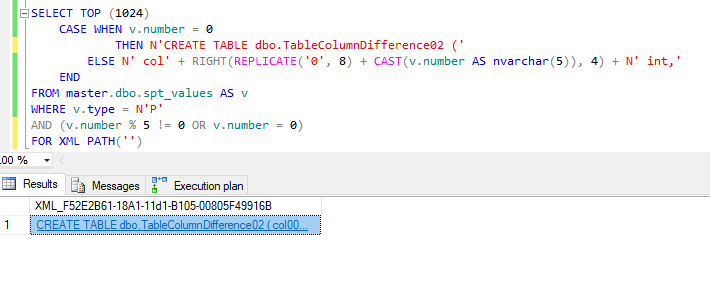
NOTE: When you copy and paste the results of this query into a new window to open it, it is going to fail. Why? Well the end of the script is going to be along the lines of colN int, and it needs to be colN int). Why is it like this? Well it was taking to damn long to script that out. Feel free to change this to work for you. Hey if you do, let me know!
Now, how I’m going to do test this, is run each method 3 times (PIVOT, UNION, and PowerShell), then measure the third run of each method. This is mainly as I want to get rid of any “cold cache” issues with SQL Server where the plan has to be compiled or the data brought into memory.
…do it Pivot
So first up is the Pivot method from the last blog post. In case you’re playing along at home (and go on, do! Why should kids get all the fun) here is the code that I’m running.
And here is our results:

What we are really after though is the stats, execution plan and time to complete for our 3rd execution. Now as much as I love reading the messages tab for the stats information, I feel with blog posts that aesthetics is king, so I’m going to be using the free tool by Richie Rump ( twitter ) “Statistics Parser“
Stats:

Execution Plan:

..do it UNION
Secondly we have what I dubbed “the UNION method” (no points for figuring out why) and the only change I’ve made to this script is to add in PARSENAME() and that’s only so that the script would..you know…work.
Results be like:

Stats:

hmm…less Scan Counts but 5 times the reads…also 5 times slower than the PIVOT method. Maybe the execution plan will be prettier?
Execution Plan:

Yeah…so…that’s…that’s different from the first plan! I was right in my comment though, there is a concatenation operator (there’s actually 2, you may need to zoom in to find them though)
…do it PowerShell
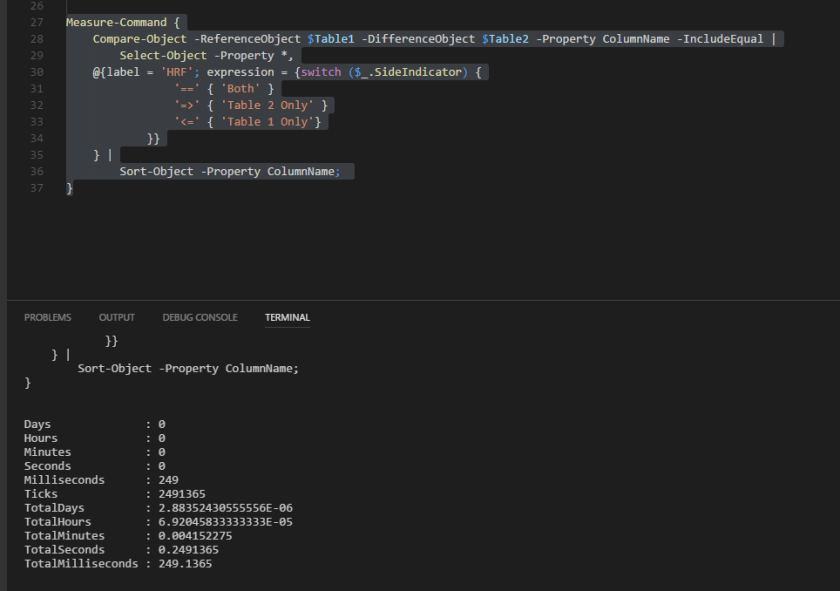
Finally we have the PowerShell method. No messing about here, let’s get straight to it! I’m going to lump all the code together in one gist and I’ll be wrapping it in Measure-Command to get the speed of the command.
Get-Results

Get-Stats:
help *execution*; help *plan*
Would you believe that I couldn’t figure out how to get an execution plan for PowerShell 🙂
If anybody knows, hit me up!
Finishing off
You know at the start of this, I was fully expecting the PowerShell to win out, followed by the UNION method, because it’s use of UNION, EXCEPT, and INTERSECT which are basically made for this kind of problem, and the PIVOT method bringing up a distant last since PIVOTs have this complexity stigma attached to them and what is complex is normally slow.
From a sheer speed point of view, the actual results are:
- Pivot
- PowerShell
- Union
Who knew!?
I don’t think this is the end of my use of PowerShell or Union operators though. I’m not going to replace all the stuff that I can with Pivots. For one I just think that PowerShell and the Union operators are just too cool!
I actually like this result for two reasons.
- There are multiple way to do something in SQL, there are good ways and better ways. The main point is whatever option you choose, make sure you know what it entails and can justify it.
Whatever works for you, works for you! - You don’t know something, test it and find out! What you think the outcome may be, may not be true.
Now if you’ll excuse me, I want to figure out if there’s a way to return execution plans with PowerShell.
One thought on “Table Column Differences with T-SQL and PowerShell – Part 2”