It got me thinking, “Huh, does SQL Server not have filters? And, if not, how can we work around that?”
So, cheers, David, for the idea for this post.
The Big Set up
We’re going to use the same setup that David has in his post
USE tempdb;
GO
CREATE TABLE z (a int, b int, c int);
GO
INSERT INTO z VALUES (1, 10, 100), (2, 20, 200), (3, 30, 300), (4, 40, 400);
GO
SELECT a,b,c FROM z;
GO
I learnt how to increase font size.
Stupid, but does it work
Now, SQL Server doesn’t have the filter option, but we can do some pretty weird things, like a SELECT...WHERE statement with no FROM clause.
SELECT
a,b,c,
[filter?] = (SELECT b WHERE b > 11)
FROM z;
GO
Does it B useful though?
So, is that it? Can we just throw that into a COUNT() function and essentially have the same thing as Postgres?
SELECT
all_rows = COUNT(*),
b_gt_11 = COUNT((SELECT b WHERE b > 11))
FROM z;
GO
B better.
Workaround
We can rewrite that strange little filter we have using an OUTER APPLY.
SELECT
a,b,c,
[filter?] = bees.bee
FROM z
OUTER APPLY (SELECT b WHERE b > 11) AS bees (bee);
GO
Same, same, but different.
Now, can we throw that in a COUNT() function?
SELECT
all_rows = COUNT(*),
b_gt_11 = COUNT(bees.bee)
FROM z
OUTER APPLY (SELECT b WHERE b > 11) AS bees (bee);
GO
B-utiful!
Things I don’t know
Postgres, yet. Still learning this one.
Why the OUTER APPLY works, but the subquery doesn’t? Let’s review the plans and see if we can identify a culprit.
Does not Compute Scalar
Strangely, the first Compute Scalar (from the left, after the SELECT) is simply a scalar operator applied to the other Compute Scalar.
It’s enough to block aggregation, though, but I’ll leave it to more specialised people than I to tell me why. I’ll just store this under “errors out” for future reference.
Performance Implications This is a test on 4 rows. What would happen if this were tens of millions of rows? … I leave that to the reader.
Welcome to T-SQL Tuesday, the brainchild of Adam Machanic ( twitter ) and ward of Steve Jones ( blog | twitter ). T-SQL Tuesday is a monthly blogging party where a topic gets assigned and all wishing to enter write about the subject. This month we have Mikey Bronowski ( blog | twitter ) asking us about the most helpful and useful tools we know of or use.
Tools of the trade are a topic that I enjoy. I have a (sadly unmaintained) list of scripts from various community members on my blog. This list is not what I’m going to talk about though. I’m going to talk about what to do with or any scripts.
I want to talk about you as a person and as a community member. Why? Because you are the master of your craft and a master of their craft takes care of their tools.
Store Them
If you are using scripts, community-made or self-made, then you should store them properly. By properly, I’m talking source control. Have your tools in a centralised place where those who need it can access it. Have your scripts in a centralised place where everyone gets the same changes applied to them, where you can roll back unwanted changes.
If you are using community scripts, then more likely than not, they are versioned. That way you’re able to see when you need to update to the newest version. No matter what language you’re using, you can add a version to them.
PowerShell has a ModuleVersion number, Python has __version__, and SQL has extended properties.
If you take care of these tools, if you store them, version them, and make them accessible to those who need them, then they will pay you back a hundredfold. You’ll no longer need to re-write the wheel or pay the time penalty for composing them. The tools will be easy to share and self-documented for any new hires. Like the adage says: Take care of your tools and your tools will take care of you.
If this was a horror movie, it would be called “The Differencing”…duh duh duh!
Time to read: ~ 5 minutes
Words: 1057
Update 2021-07-14: Marked code blocks as preformatted
The original post for this topic garnered the attention of a commenter who pointed out that the same result could be gathered using a couple of UNION ALLs and those lovely set-based EXCEPT and INTERSECT keywords.
I personally think that both options work and whatever you feel comfortable with, use that.
It did play on my mind though of what the performance differences would be…what would the difference in STATISTICS IO, TIME be? What would the difference in Execution Plans be? Would there even be any difference between the two or are they the same thing? How come it’s always the things I tell myself not to forget that I end up forgetting?
I have no idea about the last one but at least the other things we can check. I did mention to the commentor that I would find this an interesting blog topic if they wanted to give it a go and get back to me. All I can say is – Sorry, your mail must have got lost in transit. I’m sure it is a better blog post that mine anyway.
If you’re going to do it…
For this test, we’re not going to stop at a measely 4 columns per table. Oh no! For this one we’re going to go as wide as we can.
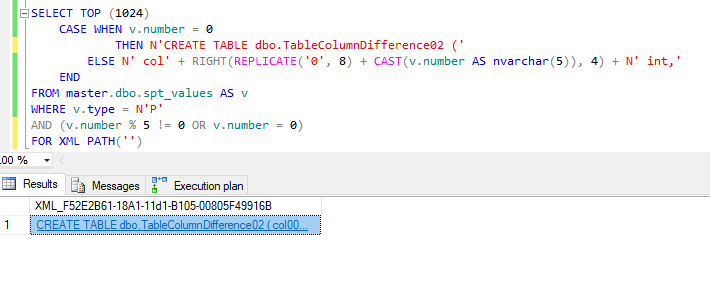
With a recent post by Kenneth Fisher ( blog | twitter ) out about T-SQL FizzBuzz, I’m going to create two tables, both of which will have incrementing column names i.e. col00001, col00002, …, col1024. Table1 will have all columns divisible by 3 removed while Table2 will have all columns divisible by 5 removed.
See, FizzBuzz can be useful!
So our table creation scripts…
SELECT TOP (1024) CASE WHEN v.number = 0 -- Change this to 02 the second run through THEN N'CREATE TABLE dbo.TableColumnDifference01 (' ELSE N' col' + RIGHT(REPLICATE('0', 8) + CAST(v.number AS nvarchar(5)), 4) + N' int,' END FROM master.dbo.spt_values AS v WHERE v.type = N'P' AND ( -- Change this to '% 5' the second run through v.number % 3 != 0 OR v.number = 0 ) FOR XML PATH('')
See Note
NOTE:When you copy and paste the results of this query into a new window to open it, it is going to fail. Why? Well the end of the script is going to be along the lines of colN int, and it needs to be colN int). Why is it like this? Well it was taking to damn long to script that out. Feel free to change this to work for you. Hey if you do, let me know!
Now, how I’m going to do test this, is run each method 3 times (PIVOT, UNION, and PowerShell), then measure the third run of each method. This is mainly as I want to get rid of any “cold cache” issues with SQL Server where the plan has to be compiled or the data brought into memory.
…do it Pivot
So first up is the Pivot method from the last blog post. In case you’re playing along at home (and go on, do! Why should kids get all the fun) here is the code that I’m running.
And here is our results:
Yup, those be columns
What we are really after though is the stats, execution plan and time to complete for our 3rd execution. Now as much as I love reading the messages tab for the stats information, I feel with blog posts that aesthetics is king, so I’m going to be using the free tool by Richie Rump ( twitter ) “Statistics Parser“
Stats:
Elapsed time: 00:00:00.136
Execution Plan:
Probably the first plan I’ve seen where the SORT isn’t the most expensive!
..do it UNION
Secondly we have what I dubbed “the UNION method” (no points for figuring out why) and the only change I’ve made to this script is to add in PARSENAME() and that’s only so that the script would..you know…work.
Yeah…so…that’s…that’s different from the first plan! I was right in my comment though, there is a concatenation operator (there’s actually 2, you may need to zoom in to find them though)
…do it PowerShell
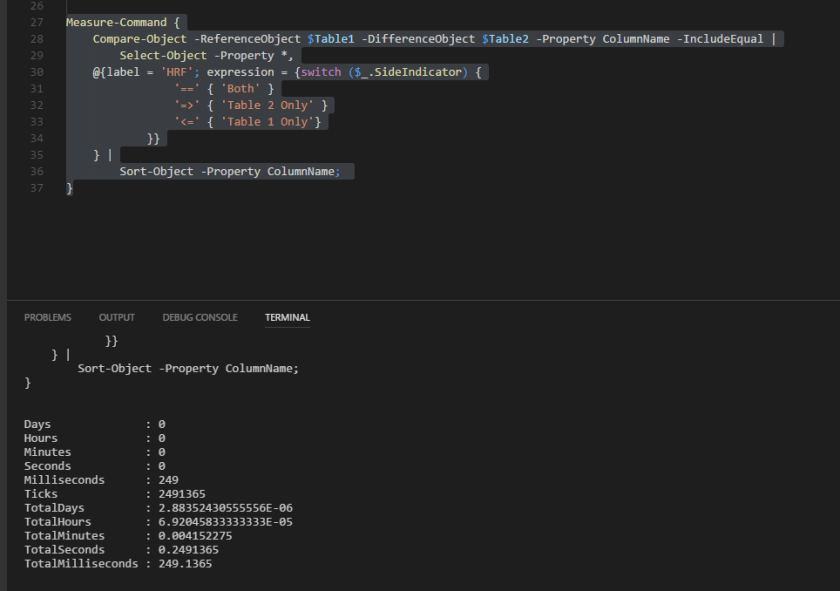
Finally we have the PowerShell method. No messing about here, let’s get straight to it! I’m going to lump all the code together in one gist and I’ll be wrapping it in Measure-Command to get the speed of the command.
Get-Results
Yeah I’m liking VS Code more and more…
Get-Stats:
Elapsed time: 00:00:00.249
help *execution*; help *plan*
Would you believe that I couldn’t figure out how to get an execution plan for PowerShell 🙂
If anybody knows, hit me up!
Finishing off
You know at the start of this, I was fully expecting the PowerShell to win out, followed by the UNION method, because it’s use of UNION, EXCEPT, and INTERSECT which are basically made for this kind of problem, and the PIVOT method bringing up a distant last since PIVOTs have this complexity stigma attached to them and what is complex is normally slow.
From a sheer speed point of view, the actual results are:
Pivot
PowerShell
Union
Who knew!?
I don’t think this is the end of my use of PowerShell or Union operators though. I’m not going to replace all the stuff that I can with Pivots. For one I just think that PowerShell and the Union operators are just too cool!
I actually like this result for two reasons.
There are multiple way to do something in SQL, there are good ways and better ways. The main point is whatever option you choose, make sure you know what it entails and can justify it. Whatever works for you, works for you!
You don’t know something, test it and find out! What you think the outcome may be, may not be true.
Now if you’ll excuse me, I want to figure out if there’s a way to return execution plans with PowerShell.
I’m going to point people to this that have “My Group By isn’t working” questions…
The Joys of SQL:
Did you know that the SQL language allows you to do amazing analysis of data such as aggregate functions?
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id,
t.request_id;
0’s! Amazing!
The Pains of SQL:
But…if you forget to put in the GROUP BY clause, as a ski instructor once said, you’re going to have a bad time!
Pizza…French Fries…Pizza
The Repetitiveness of Questioners:
So some eager yet lost scholar ventures into this land of aggregate functions, reads the error message and adds in a GROUP BY clause.
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id;
Trawling the bulletin boards, question sites, and forums – okay maybe a quick question online, it’s called poetic exaggerationpeople! – they eventually learn the folly of their ways and correct their mistake.
SELECT t.session_id,
t.request_id,
SUM(t.user_objects_alloc_page_count) AS UserObjectAllocated,
SUM(t.user_objects_dealloc_page_count) AS UserObjectDeallocated
FROM sys.dm_db_task_space_usage AS t
GROUP BY t.session_id,
t.request_id;
PIZZA!
The Euphoria of SQL Prompt:
Now I consider myself lucky that work has invested in the RedGate tools, and right now, especially SQL Prompt.
I’m not going to talk about “Save and Recover Lost Tabs” – saved my ass many times.
I’m not going to talk about “Code Formatting” – saved my sanity many times.
I’m going to talk about “Autocomplete”.
A well-known secret with SQL Prompt’s autocomplete is the snippets feature. With this, you can increase your productivity by 75% from typing out G R O U P [space] B Y and instead use gb and hit tab.
Wait? I can order Pizza?
The Ecstasy of SQL Prompt:
Do not get me wrong, a 75% increase in productivity? I’ll take that!
That is a well-known secret though, and it’s slightly hard to get excited about a well-known secret.
However, what if I told you that SQL Prompt had another lesser-known secret that can increase your productivity and ensure that you do not forgot to add the necessary columns to your GROUP BY clause?
Interested? Ah c’mon!
You sure you’re not interested?…. That’s better!
So first of all, let us increase the number of non-aggregated columns in our SELECT to include database_id, is_remote_work, and exec_context_id. Including our session_id and request_id these are all columns that we are going to need to add to our GROUP BY clause, because…well…business logic.
Only problem is ain’t nobody got time for that.
SQL Prompt knows this and adds the following little snippet after a GROUP BY autocomplete.
Whoa! Whoa! You can deliver Pizza to me?
Hitting tab on that includes everything in the SELECT that is not part of an aggregate function, leaving us to concern ourselves with loftier things…
Like whatever happened to Pizza in 30 mins or free?
Pizza:
Now I don’t work for pizza RedGate, I’m not affiliated with them, and I don’t get any money off of them. In fact, I’d say that they’d happily pay me not to write about them but when I found this autocomplete feature, I got too happy not to share it!
So save yourself the trouble of typing everything out and spare yourself the pain of error messages.
Use this lesser-known secret and have more time for pizza.
LIKE a function… now the song is stuck in your head!
… I’m not sorry…
Start: (‘abc%’)
Ever heard of “Osmosis”? You know, the…
process of gradual or unconscious assimilation of ideas, knowledge, etc.
For the longest time, that was how I thought people learned in SQL Server. You hang around a technology for long enough and the information about it slowly trickles into your brain.
I would hazard that the vast majority of people learn like this. They work with something long enough and slowly they develop, if not a mastery of the subject, then a familiarity with it.
That’s how I learned Transact-SQL anyway.
Working in a help desk, trouble-shooting stored procedures and ad hoc statements; cranking out reports left, right and center, slowly absorbing the differences between INNER, LEFT, RIGHT, and FULL joins. Realizing that there is a vast difference between excluding results with a WHERE clause and with a HAVING clause.
Ahh good times!
However, now I’m in the mindset that if you really want to learn something then study it; purposefully and deliberately.
And with all the new features being released for SQL Server 2016, you would be amazed at what I can learn about features that were released in SQL Server 2008.
So here’s some little known facts I learned about LIKE
Middle: (‘%lmnop%’)
Safe to say, that we’ve all used LIKE, we’ve all seen LIKE, and we’re probably all going to continue to use LIKE.
But are we using it to the best of our ability?
I wasn’t.
So let’s test out this bad boy using the WideWorldImporters database, see if we can find everyone with the first name of Leyla.
Simple right? And because [Sales].[Customers] uses the full name, we have to use LIKE.
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Leyla%';
GO
LEYYYYla!!!!
Now a developer comes along and says “Wait a second, my sister is Leila”. So we try to cheat and add a wildcard in there.
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'le%a%';
GO
…you got me on my knees…
Leonardo!? Well I suppose he does count in this situation, but there’s 2 characters between the ‘e’ and the ‘a’ and I only wanted one.
Well you can specify only 1 wildcard with the LIKE function by using the underscore (‘_’), so let’s try that.
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Le_la%';
GO
…singing darlin’ please…
Yes, I cheated and inserted that extra name ‘Lejla’.
Call it Poetic Licence but I only used it to show that we still have options if this is not the results that we want. We are only interested in ‘Leyla’ and ‘Leila’.
‘Lejla’, while a lovely name I’m sure, is not what we require right this second. So what are we to do?
Well, did you know that LIKE has the range function as well? What’s range got to do with it? Well, what happens if we only put in a range of 2 characters?
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Le[iy]la%';
GO
….darlin’ won’t you hear my foolish cry!
There we go! Only the results that we want and none of that Lejla, Leonardo business.
Now you could argue with me (I encourage it actually. How else am I to learn?) and say that you would never do it this way. That it is much easier to do something along the lines of this:
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Leyla%'
OR CustomerName LIKE 'Leila%';
GO
I’ll admit that the above reads a lot easier, but it doesn’t scale very well though. What happens if we want to include the Leala, Lebla, Lecla,….all the way to Lenla’s? Are you going to write out 15 different clauses? 1 for each different character?
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Leyla%'
OR CustomerName LIKE 'Leila%'
OR ....
OR ...
OR ..
OR .
GO
Or are you going to go back to ranges and do a clean, efficient, single range?
SELECT CustomerName
, CustomerID
FROM Sales.Customers
WHERE CustomerName LIKE 'Le[a-ny]la%';
GO
Now I’d argue that that is a lot more readable than an endless list of OR clauses tacked on to the end of a script.
Oh wait, it’s Layla isn’t it? Not Leyla!
End: (‘%xyz’)
There is a lot more you can do with the LIKE function. Just because you may encounter this little guy every day does not mean that you know it.
Don’t shy away from the fundamentals. Every little bit that you learn can and more than likely will be used to improve your skills and make you better.
Hopefully these little tidbits of knowledge will sink in…just like osmosis 🙂
Update: Thanks to “kuopaz”, for pointing out that I had forgotten to add the unnamed constraint to the example where I say unnamed constraints will work fine.
Introduction:
Kenneth Fisher (b | t) recently wrote about Re-Evaluating Best Practices and, reading his post, I couldn’t help but agree with him. Especially with regard to:
Times change, knowledge changes so best practices have to change. Don’t rest on your knowledge or the knowledge of others. Make sure you understand not only what the best practice is but why it’s the best practice. And then question it.
Kenneth Fisher
Now I’m not going to bring up the Microsoft PLE of 300 advice as that example has been taken out and waved in front of people’s faces so many times that I feel it’s lost it’s impact and, as far as I am aware, it’s the only case where the best practice is so widely ineffectual.
However, the statement…
Make sure you understand not only what the best practice is but why it’s the best practice.
Kenneth Fisher
… is, for me, the crucial statement in his post and the catalyst for the following post as I’ve fallen for a case where the best practices are not applicable; Naming Constraints.
Naming Constraints:
In this post, we are going to be looking at the best practice of giving logical, descriptive names to constraints in tables.
The following code is going to create a table called dbo.NamingConstraints with an Primary key column, a named constraint column and an unnamed constraint column.
We can check these constraints with the following two queries, the first for the Primary key, and the second for the CHECK constraints, with the results in Figure 1.1.
Constraint Check:
SELECT
kc.[name],
kc.[is_system_named],
kc.[type_desc],
kc.[unique_index_id]
FROM
[sys].[key_constraints] AS kc
WHERE
kc.[parent_object_id] = OBJECT_ID(N'[dbo].[NamingConstraints]', N'U');
SELECT
cc.[name],
cc.[is_system_named],
cc.[type_desc],
cc.[is_disabled],
cc.[definition]
FROM
[sys].[check_constraints] AS cc
WHERE
cc.[parent_object_id] = OBJECT_ID(N'[dbo].[NamingConstraints]', N'U');
Constraints are best used to ensure referential and data integrity. Therefore they are commonly seen when data considered against business logic is attempted to be inserted into the database, and error messages are thrown.
When these error messages occur, they normally are passed into error logs from whatever application is integreated into our database. In these cases it is easier to deal with descriptive names than non descriptive ones.
Taking our two CHECK constraints as examples, if we were to introduce error messages…
Looking at the first error message reported (Figure 2.1), we know from the error message that something is wrong in the Table dbo.NamingConstraints and the column is UnNamedConstraint but that is it. If this table had multiple constraints, and we weren’t the one to create this table and the constraints, we would have to do some (potentially lengthy) investigation to figure out what is causing the error and then correct it.
Figure 2.1
Compare that with the error message for our named constraint (Figure 2.2).
Figure 2.2
As we have a proper, descriptive constraint name here, straight away we can say that the error occurred as we tried to insert a value that was not greater than 0.
When Naming Constraints is not applicable.
TL;DR
Do not name constraints on temporary tables.
Why?
Why as in what would a use case for this be? I use this a lot to step through code with different variables, especially with stored procedures.
Two windows, side by side, running them step by step and comparing the results in each.
…I know, fun right?…
Or why as in why should you not name constraints on temporary tables? Well that’s going to require a bit more detail.
So if we were troubleshooting a procedure and attempted to pass results into a temporary table…
CREATE TABLE #Temp02 (
[Col1] int IDENTITY(1, 1) NOT NULL,
[Col2] varchar(256) CONSTRAINT [Col2_neq_Forbidden] CHECK ([Col2] <> 'Forbidden')
);
INSERT INTO #Temp02 ([Col2])
SELECT
[name]
FROM
[sys].[all_objects];
SELECT
*
FROM
#Temp02;
… we should have no problem.
Figure 3.1
But say we try to do that in two seperate windows…
Figure 3.2
… Big, angry error message telling usthat it could not create the constraint and that an object alreadt exists in the database.
Now say that we were to not explicitly name the constraints on these tables?
CREATE TABLE #Temp02
(
Col1 int IDENTITY(1,1) NOT NULL,
Col2 varchar(256) CHECK (Col2 <> 'Forbidden')
);
INSERT INTO #Temp02 (Col2)
SELECT name FROM sys.all_objects;
SELECT * FROM #Temp02;
GO
Figure 3.3 (works with an unnamed constraint as well)
No problem! Since we have not explicitly named the constraint, SQL Server does not violate it’s rule for identifiers and so does not throw an error message!
Caveats
Yes, I know that this could be classed as an extreme edge case but that is not the caveat that I’m talking about here.
If you are in the habit of not skipping over reading the actual SQL code, you may be wondering to yourself.
Well, the temp tables are called the same name and they should follow the rules for identifiers as well, no? Why aren’t they throwing an error?
Well that’s because temp tables are treated a bit differently than other objects.
Consider the following example where we try to find our temp table in TempDB:
SELECT * FROM tempdb.sys.tables WHERE name = '#Temp02';
Figure 4.1
Nothing. It doesn’t exist. But we didn’t drop it and we haven’t closed the scope so it can’t have just disappeared!
If we change our select statement to the LIKE operator with an ending %…
SELECT * FROM tempdb.sys.tables WHERE name LIKE '#Temp02%';
Figure 4.2
SQL Server, knowing that temp tables could get created multiple times concurrently (especially if created in Stored Procedures), gets around the rule for identifiers with temp tables by adding a unique suffix onto each temp table that is created.
Therefore, it doesn’t violate the rule, it doesn’t error out and multiple concurrent sme-named temp tables can be created.
Why doesn’t this unique suffix happen with constraints aswell? Is this on purpose? By Design? Well the only answer I can give is, I don’t know.
But what I do know is that, in these cases with temp, don’t name your constraints.
In my last post, I was looking into creating new temporary tables from a SELECT INTO syntax when I ran across an issue that I couldn’t explain.
I realised that a situation like that cannot be allowed to continue on a blog post about SQL Server so I documented what I was experiencing (probably pretty poorly I may add) and said that when I had an answer, I would let you know.
However, I will try as best I can to explain it, mainly for myself though so I can look back on it.
Summary of the problem:
We have a table with an identity value of 1,000. When we select a subset of that table into a new table the identity value of the new table decreases to match the highest identity value of that subset.
From initial investigations, there is no visible evidence to show how this is achieved, so how is this happening?
Code:
SELECT * INTO #temp FROM dbo.A WHERE x1 = 1;
SELECT * FROM #temp;
Red Herrings:
When running a SELECT INTO query, if you were to enable STATISTICS PROFILE beforehand,
SET STATISTICS PROFILE ON;
SELECT A_ID, x1 INTO #Test FROM dbo.A WHERE x1 = 1;
…you will see an Argument column with the following code:
The second phase performs an insert into the table the first phase created. This insert is done withidentity_insert semantics, so the identity values from the source table end up in the destination, unchanged. The highest value actually inserted is set as the last value used. You can use IDENT_CURRENT or sys.indentity_columns to see it.
So there is no addition/subtraction going on here.
SQL Server is simply going:
> Are we done inserting? We are? Great, what was that last identity value? 998? Great, that’s your new identity value for this table!
I am not pro-cursor. I am not, however, extremely anti-cursor.
I think that if there is a cursor used for a certain problem it just means we don’t know enough about the problem, the data or the code to think of a better solution.
But I’ve had an experience with cursors and, for my cases, found a better way.
That is what this blog post is going to be about, a case where we were using a cursor until we realised a better solution for it.
Background:
We have a weird table.
It’s our fault though as we’ve made it weird, we haven’t properly normalised it and it’s basically just a massive catch-all for records and for some strange reason, only 1 in 10 records have a ticket number.
So let’s create it!
-- Create the test table.
CREATE TABLE
[dbo].[ProductActions]
(
[product_action_id] INT IDENTITY(0, 1) PRIMARY KEY,
[product_id] INT,
[allowed_action_id] INT,
[ticket_number] VARCHAR(20),
[date_actioned] DATE
);
-- Populate it.
WITH
L0 AS(SELECT 1 AS c UNION ALL SELECT 1),
L1 AS(SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS(SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS(SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS(SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS(SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B)
INSERT dbo.ProductActions
(product_id, allowed_action_id, date_actioned)
SELECT TOP (10000000)
product_id = ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) % 5,
allowed_action_id = (ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) + 5) / 5,
date_actioned = CAST(DATEADD(DAY, (SELECT ABS(CHECKSUM(NEWID())) % 50000), 0) AS DATE)
FROM L5;
UPDATE dbo.ProductActions
SET ticket_number = (CASE
WHEN product_action_id % 10 = 0
THEN 'TCKT'
+ REPLACE(QUOTENAME(product_action_id, ''''),'''','')
ELSE NULL
END);
…that took around 1 minute for 10,000,000 records, including the create and update statements…
Now say something diabolical happens, a bad delete statement, a disgruntled employee who just won the lottery, a chimpanzee riding on a segway, whatever but for some reason all the records holding our ticket numbers get deleted.
However, thankfully (not sure if that’s the right word) we have Excel sheets of the records that were dropped.
… 9 seconds! 9 seconds for that wealthy employee/chimpanzee to cause havoc…
However, we don’t have everything; we have the product_id and the allowed_action_id.
So the business tells us that the dates don’t matter, it just needs those records back and those ticket numbers!
What we did:
Cursors. (I know, I’m sorry.)
However, we had problems.
Our table had a lot of traffic so we weren’t guaranteed an unbroken sequential range of identifiers that we could update.
And we couldn’t remove these foreign inserts from our range as we had no way of identifying which was our records and which were foreign records.
So we created a cursor. Not a performance tuned cursor since we were relatively new to SQL at the time but a run-of-the-mill, Google what it is and grab the template off the internet cursor.
Steps:
Import the records into a holding table
Give the table a sequential identifier for ordering
Get the first record
Insert it into the original table
Grab the identity of the insert we just inserted
Update it to have the correct ticket number
Grab the next record and repeat steps 4 – 6
Finish
All together 8 steps (although steps 3 – 7 are done around 1 million times) but how fast is it?
Step 2:
ALTER TABLE
dbo.DeletedRecordsPaper
ADD [ID] INT IDENTITY(0, 1);
GO
…around 34 seconds, surprisingly long…sign of things to come?…
Steps 3 – 7:
DECLARE @prodID INT,
@allowed INT,
@entered INT;
-- Start of Step 3
DECLARE FillMissingRecords
CURSOR FOR
SELECT product_id, allowed_action_id
FROM dbo.DeletedRecordsPaper
ORDER BY ID ASC;
OPEN FillMissingRecords
FETCH NEXT
FROM FillMissingRecords
INTO @prodID,
@allowed
WHILE @@FETCH_STATUS = 0
BEGIN -- Step 4
INSERT dbo.ProductActions
(product_id, allowed_action_id, date_actioned)
SELECT @prodID,
@allowed,
GETDATE();
-- Step 5
SELECT @entered = SCOPE_IDENTITY();
-- Step 6
UPDATE dbo.ProductActions
SET ticket_number = 'TCKT' + CAST(@entered AS varchar(10))
WHERE product_action_id = @entered;
-- Step 7
FETCH NEXT
FROM FillMissingRecords
INTO @prodID,
@allowed
END
CLOSE FillMissingRecords
DEALLOCATE FillMissingRecords;
How’d it do? Well it worked; 1 million records took 9 minutes and 35 seconds though.
…9 minutes and 35 seconds…9 minutes and 35 seconds?!?…I could have recreated the table 9 and a half times in that time! I knew it was going to be slow, I even went out and got a coffee while I was waiting but C’MON!!!!…
So altogether, with the adding of the sequential identifier, it took 10 minutes to run.
Now I can’t remember why exactly but this happened a few times so we had to run this a few times.
Looking at this issue the main problem that we could see was that we needed to know what records we had inserted to update them with a ticket number.
We thought that we couldn’t figure out what we had inserted without using SCOPE_IDENTITY, we didn’t know about the inserted table, we didn’t know about variable tables, essentially we didn’t know about OUTPUT.
Steps:
Import the records into a holding table
Declare a holding table for the identities
Insert all the records into the original table and output the values to our holding table
Update all the records inserted to have the correct ticket number
Finish
All together 5 steps, already an improvement, but that’s just steps, not performance. Is it an actual performance improvement?
…to be honest, if it was anyways faster than 9 minutes, I’d be happy…
-- Step 2
DECLARE @entered
TABLE
(
entered_id INT
);
-- Step 3
INSERT dbo.ProductActions
(product_id, allowed_action_id, date_actioned)
OUTPUT inserted.product_action_id
INTO @entered
SELECT product_id,
allowed_action_id,
GETDATE()
FROM dbo.DeletedRecordsPaper;
-- Step 4
UPDATE pa
SET ticket_number = 'TCKT' + CAST(entered_id AS varchar(10))
FROM dbo.ProductActions AS [pa]
JOIN @entered AS e
ON pa.product_action_id = e.entered_id;
29 SECONDS!!!! 1 million rows in 29 seconds!
So we’ve gone from 1 million rows in 9 minutes 35 seconds (~1,730 rows a second) to 1 million in 29 seconds (~34,482 rows a second).
…those results flustered me so much that I forgot maths so if anybody wants to work out that improvement percentage, please let me know. I want to write that one down!…
Conclusion:
The most dangerous phrase in the English language is probably “what does this button do?”
The second most dangerous is “we’ve always done it that way”.
There’s always room for improvement testing (on the right system i.e. NOT PRODUCTION) and OUTPUT over CURSORS any day.