
Words: 398
Time to read: ~ 2 minutes
tl;dr : Give it an alias! ( select ‘0’ AS [Zero]; )
Continue reading “How Can I Replace “No column name” With A Word In SQL Server?”
An ode to a knowledge seeker
Words: 398
Time to read: ~ 2 minutes
tl;dr : Give it an alias! ( select ‘0’ AS [Zero]; )
Continue reading “How Can I Replace “No column name” With A Word In SQL Server?”
There are some properties that I just don’t want to see…
Words: 394
Time to read: ~ 2 minutes
Update 2019-07-24: Newer blog post here : https://nocolumnname.blog/2019/07/24/excludeproperty-in-powershell-core/
Nice, short, simple blog post today.
Working on getting data file information from the SQL Server SMO objects:
<br>
foreach ($DataFile in $db.FileGroups.Files) {</p>
<p> $DataFile</p>
<p>}<br>

Hmm, Properties, ExecutionManager, and URN (hidden from view) are not needed. That is not a problem, I’ll just pipe them to Select-Object and include them in the -ExcludeProperty parameter.
So we change our code to the following:
</p>
<p>foreach ($DataFile in $db.FileGroups.Files) {</p>
<p>$DataFile |<br>
Select-Object -ExcludeProperty Urn,<br>
Properties,<br>
ExecutionManager</p>
<p>}<br>

What the…? I excluded these guys! Do they not know the meaning of “Exclude”?!
As Kevin Feasel ( blog | twitter | CuratedSQL ) once said “Get-Member early and Get-Member often“, I’d like to add to that:
Get-Member early and Get-Member often…and don’t forget to Get-Help!
<br> help Select-Object -ShowWindow<br>

Now I’m interested in the -ExcludeProperty parameter but I read the full thing, it’s not that big anyway. Thankfully the help, well, helps me.

Main point here is:
This parameter is effective only when the command also includes the Property parameter.
I change up my code to include the -Property * and see how it works…
<br>
foreach ($DataFile in $db.FileGroups.Files) {</p>
<p> $DataFile |<br>
Select-Object -Property * -ExcludeProperty Urn,<br>
Properties,<br>
ExecutionManager</p>
<p>}<br>

Now, there is nothing here that I would consider a ground-breaking, earth-shattering revelation. I had a problem, resolved it, and decided to share it.
This is quite possibly the shortest post I’ve ever written and there’s a reason for that; #SQLNewBlogger.
Blog posts don’t have to have these big revelations for you. It seems to help, yeah, but that’s mainly because if you feel passionate about something, it comes across in your writing. Besides, what you consider trivial, other people may never have thought of or encountered before. So go on! Give it a go!
Got a problem, write it up.
Got an opinion, voice it.
Got a script, share it.
Got it? Good!
Making it clear to anyone reading this but this post is about SQL Server even though I start off talking a bit about PostgreSQL.
…I know, weird right?…
I have a PostgreSQL instance on my home laptop that I haven’t used yet.
I intend to start using it soon as a sort of hobby as I feel that there are things to be learned about databases from it. Like comparing features available to PostgreSQL that are not in SQL Server and vice-versa or the different ways the same tasks are accomplished in both platforms.
However SQL Server is the platform used in my work, I still have so much to learn with it (especially with 2016 coming out!!!), and I just find it so damn interesting so I haven’t touched PostgreSQL yet.
All that being said, I have signed up to few newsletters from PostgreSQL (General, Novice, etc) and they are fascinating.
Unfamiliar words like pglogical and rsync are combined with known words like publisher and subscriber and the community itself is so vast and supportive that it rivals the #SQLFamily (from what I’ve seen and yes. I am being biased to SQL Server 🙂 ).
One of those newsletters was regarding a problem a user was having with creating databases.
When he would create a new database it was not empty as he expected but was filled with user tables, logins, etc.
What was going on?
The explanation was pretty much what you would expect, just called by a different name.
He had basically written to his Model database (called template1 in PostgreSQL) sometime ago without realising it.
PostgreSQL has the following syntax with creating databases:
CREATE DATABASE DatabaseName WITH TEMPLATE TemplateName
The new database settings are created from whatever template is specified using the WITH TEMPLATE syntax (defaults to template1 apparently).
This works the same as SQL Server, the new databases inheriting the settings from the Model system database, but in our case it is implicit. There is no call for WITH TEMPLATE Model.
This is perfectly valid syntax.
CREATE DATABASE DatabaseName
The only difference that I can tell at the moment is that PostgreSQL can have multiple different templates while SQL Server has just one; Model.
Is this restriction on database templates a good thing or a limitation? Personally I go with the former but you may feel differently.
…Multiple Models?…
This brought me back to the system databases and there was something that I realised.
A lot of new users, and I was included in this list not too long ago, do not think about the system databases.
I’m not sure I can fault them as well as it’s probably not a priority. There is so much to learn with regard to DDL statements, DML statements, Deadlocking, General T-SQL, etc, that the system databases are just a little folder under Databases that does not get opened.

However, and I can’t stress these enough, these are important!
And that is just scratching the surface!
Take care of these databases, do not limit yourself to looking after just the user databases.
They are not the only databases that need to be backed-up and they are not the only databases that can experience corruption.
I’m hoping that you believe me with this but, unfortunately, the best lessons are learned.
You should have a destructive sandbox SQL Server, (NOT PRODUCTION!!!), hopefully a little laptop at home to call your own; something that nooby else would mind you destroying basically.
Choose a system database, anyone will do; delete that database, drop it, whatever you want just make it unavailable and see how far you can get using SQL Server.
…Hell isn’t it?…
Now imagine that happened unexpectantly and unwanted on a Monday morning because you weren’t taking care of your system databases.
Take care of your System Databases.
Time to read: ~ 6 minutes
Words: 1151
Update: Thanks to “kuopaz”, for pointing out that I had forgotten to add the unnamed constraint to the example where I say unnamed constraints will work fine.
Kenneth Fisher (b | t) recently wrote about Re-Evaluating Best Practices and, reading his post, I couldn’t help but agree with him. Especially with regard to:
Times change, knowledge changes so best practices have to change. Don’t rest on your knowledge or the knowledge of others. Make sure you understand not only what the best practice is but why it’s the best practice. And then question it.
Kenneth Fisher
Now I’m not going to bring up the Microsoft PLE of 300 advice as that example has been taken out and waved in front of people’s faces so many times that I feel it’s lost it’s impact and, as far as I am aware, it’s the only case where the best practice is so widely ineffectual.
However, the statement…
Make sure you understand not only what the best practice is but why it’s the best practice.
Kenneth Fisher
… is, for me, the crucial statement in his post and the catalyst for the following post as I’ve fallen for a case where the best practices are not applicable; Naming Constraints.
In this post, we are going to be looking at the best practice of giving logical, descriptive names to constraints in tables.
The following code is going to create a table called dbo.NamingConstraints with an Primary key column, a named constraint column and an unnamed constraint column.
CREATE TABLE [dbo].[NamingConstraints] (
[ID] int IDENTITY(1, 1) CONSTRAINT [PK_NamingConstraint_ID] PRIMARY KEY,
[NamedConstraint] int CONSTRAINT [NamedConstraint_gt_0] CHECK ([NamedConstraint] > 0),
[UnNamedConstraint] varchar(50) CHECK ([UnNamedConstraint] <> 'Forbidden')
);
We can check these constraints with the following two queries, the first for the Primary key, and the second for the CHECK constraints, with the results in Figure 1.1.
SELECT
kc.[name],
kc.[is_system_named],
kc.[type_desc],
kc.[unique_index_id]
FROM
[sys].[key_constraints] AS kc
WHERE
kc.[parent_object_id] = OBJECT_ID(N'[dbo].[NamingConstraints]', N'U');
SELECT
cc.[name],
cc.[is_system_named],
cc.[type_desc],
cc.[is_disabled],
cc.[definition]
FROM
[sys].[check_constraints] AS cc
WHERE
cc.[parent_object_id] = OBJECT_ID(N'[dbo].[NamingConstraints]', N'U');

As Figure 1.1 shows us when we don’t specify a name for a constraint, SQL Server will assign a name to that constraint for us.
Constraints are best used to ensure referential and data integrity. Therefore they are commonly seen when data considered against business logic is attempted to be inserted into the database, and error messages are thrown.
When these error messages occur, they normally are passed into error logs from whatever application is integreated into our database. In these cases it is easier to deal with descriptive names than non descriptive ones.
Taking our two CHECK constraints as examples, if we were to introduce error messages…
/* UnNamed Constraint Violated */
INSERT INTO [dbo].[NamingConstraints] (
[NamedConstraint],
[UnNamedConstraint]
)
VALUES (
1, 'Forbidden'
);
/* Named Constraint Violated */
INSERT INTO [dbo].[NamingConstraints] (
[NamedConstraint],
[UnNamedConstraint]
)
VALUES (
-1, 'Allowed'
);
Looking at the first error message reported (Figure 2.1), we know from the error message that something is wrong in the Table dbo.NamingConstraints and the column is UnNamedConstraint but that is it. If this table had multiple constraints, and we weren’t the one to create this table and the constraints, we would have to do some (potentially lengthy) investigation to figure out what is causing the error and then correct it.

Compare that with the error message for our named constraint (Figure 2.2).

As we have a proper, descriptive constraint name here, straight away we can say that the error occurred as we tried to insert a value that was not greater than 0.
Do not name constraints on temporary tables.
Why as in what would a use case for this be? I use this a lot to step through code with different variables, especially with stored procedures.
Two windows, side by side, running them step by step and comparing the results in each.
…I know, fun right?…
Or why as in why should you not name constraints on temporary tables?
Well that’s going to require a bit more detail.
SQL Server requires a unique name on it’s objects as they must comply with the rules of identifiers.
So if we were troubleshooting a procedure and attempted to pass results into a temporary table…
CREATE TABLE #Temp02 (
[Col1] int IDENTITY(1, 1) NOT NULL,
[Col2] varchar(256) CONSTRAINT [Col2_neq_Forbidden] CHECK ([Col2] <> 'Forbidden')
);
INSERT INTO #Temp02 ([Col2])
SELECT
[name]
FROM
[sys].[all_objects];
SELECT
*
FROM
#Temp02;
… we should have no problem.

But say we try to do that in two seperate windows…

… Big, angry error message telling usthat it could not create the constraint and that an object alreadt exists in the database.
Now say that we were to not explicitly name the constraints on these tables?
CREATE TABLE #Temp02
(
Col1 int IDENTITY(1,1) NOT NULL,
Col2 varchar(256) CHECK (Col2 <> 'Forbidden')
);
INSERT INTO #Temp02 (Col2)
SELECT name FROM sys.all_objects;
SELECT * FROM #Temp02;
GO

No problem! Since we have not explicitly named the constraint, SQL Server does not violate it’s rule for identifiers and so does not throw an error message!
Yes, I know that this could be classed as an extreme edge case but that is not the caveat that I’m talking about here.
If you are in the habit of not skipping over reading the actual SQL code, you may be wondering to yourself.
Well, the temp tables are called the same name and they should follow the rules for identifiers as well, no? Why aren’t they throwing an error?
Well that’s because temp tables are treated a bit differently than other objects.
Consider the following example where we try to find our temp table in TempDB:
SELECT * FROM tempdb.sys.tables WHERE name = '#Temp02';

Nothing. It doesn’t exist. But we didn’t drop it and we haven’t closed the scope so it can’t have just disappeared!
If we change our select statement to the LIKE operator with an ending %…
SELECT * FROM tempdb.sys.tables WHERE name LIKE '#Temp02%';

SQL Server, knowing that temp tables could get created multiple times concurrently (especially if created in Stored Procedures), gets around the rule for identifiers with temp tables by adding a unique suffix onto each temp table that is created.
Therefore, it doesn’t violate the rule, it doesn’t error out and multiple concurrent sme-named temp tables can be created.
Why doesn’t this unique suffix happen with constraints aswell? Is this on purpose? By Design?
Well the only answer I can give is, I don’t know.
But what I do know is that, in these cases with temp, don’t name your constraints.
When working with SQL Server, you are going to be using TempDB; that is a certainty.
Using temporary tables, however, isn’t a certainty.
I’m taking it for granted that at one time or another you have used them but it’s not something I can say for certain.
…if you aren’t using temporary tables AT ALL, please let me know what you’re using SQL Server for. I’ll either be impressed or shocked!…more than likely shocked…
However, one of the features that I find with temporary tables is that they inherit the identity from whatever table they were created from, and more often than not, this is not the identity that you want them to have.
…I mean if we wanted them to have that identity, we would have just used the base table, right?…
Now I have ways around this that I’ll blog about later on .
However, while working with these temporary tables and their identites, I found something that I just can’t explain yet and thought I would blog about it so when I do figure it out I can look back at this and call myself all kinds of names for being so stupid.
So first of all, let’s set up our base table:
USE tempdb; GO -- Create our base table CREATE TABLE dbo.A (A_ID INT IDENTITY(1, 1), x1 INT, noise1 int DEFAULT 1, noise2 char(1) DEFAULT 'S', noise3 date DEFAULT GETUTCDATE(), noise4 bit DEFAULT 0); -- Create random data between the range of [0-3] INSERT INTO dbo.A(x1) SELECT s1000.n FROM ( SELECT TOP (10) n = 1 FROM sys.columns) AS s10 -- 10 CROSS JOIN ( SELECT TOP (10) n = 1 FROM sys.columns) AS s100 -- 10 * 10 CROSS JOIN ( SELECT TOP (10) n = ABS(CHECKSUM(NEWID())) % 4 FROM sys.columns) AS s1000; -- 100 * 10 SELECT * FROM dbo.A;
Random-ish results but should be something like this:

Now, SQL Server has a useful little Database Engine Stored Procedure called sp_help that, along with a plethora of other useful information, can return a result set on identity.
If we query our table, we would get the following results:
EXECUTE sp_help 'dbo.A';

What this is telling us is that:
…little tip: check out Tools -> Options -> Keyboard -> Query Shortcuts… you can just highlight a table and hit “Alt + F1” and you have the same results as running the above query…Efficiency for the win!…
which is great if we wanted to know what we started off with, but what about looking into the future? What about knowing what’s going to get inserted next?
Well for the identity column, we can!
DBCC CHECKIDENT(), passing in your table name.
NOTE: I’ve just given you a potentially dangerous command as it has some optimal parameters that can break stuff. Do me a favour and make sure you’re not on Production.
…see the above? How it’s in bold? Do me a favour and double check you’re not on Production? Cheers!…
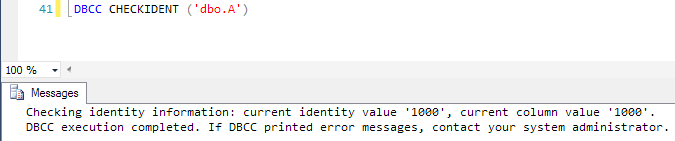
so we’ve looked into the future and we can tell that with sp_help and DBCC CHECKIDENT, our future identity will be:
DBCC CHECKIDENT().current identity value + sp_help.increment
Now say that part of our query is only interested in rows where x1 = 1.
The most basic way to create our temporary table with this information is probably the one that the majority would use:
SELECT * INTO #temp FROM dbo.A WHERE x1 = 1; SELECT * FROM #temp;
…Nice, simple, easy. 3 things that we want….

And if we were to ALT+ F1 #temp we would get the following:

…Same identity!…
So with the same identity, we have the same current identity value, right?
DBCC CHECKIDENT('#temp')

…WRONG!…
Now I like this.
I appreciate this.
I’m thankful for this.
But I’m not sure why exactly this happens, apart from SQL Server is smart enough to know that it’s not going to need the exact same current identity value for this new table.
Using a (slightly depreciated) command
SET STATISTICS PROFILE ON; SELECT * INTO #temp FROM dbo.A WHERE x1 = 1;

..it seems like SQL Server is changing the identity for you…
Now just to make this even more confusing, we run the following which for me shows that the last x1 value is 2.
SELECT * FROM dbo.A ORDER BY A_ID DESC;

So what I’m expecting is that if we were to input this into a temporary table, we wouldn’t expect to see that setidentity…-7.
SET STATISTICS PROFILE ON; SELECT * INTO #temp2 FROM dbo.A WHERE x1 = 2;

…But it’s there!…
Fine, okay so, just means that our current identity value has been changed!
So we run our DBCC CHECKIDENT and…
DBCC CHECKIDENT ('#temp2')

No change.
And that’s my problem!
I don’t have an answer for this at the moment but when I figure this out, I’ll let you know, and if anyone has the answer, feel free to share 🙂
But at least I have a partial answer:
Question: When subtracting 7 from a value equal no change?
Answer: When SQL Server is involved.
This blog post is not what I was intending to write, at least not so early in my list of blog postings. Mainly due to the fact that it’s main issue is around SARG-ability which I think is a bit more advanced than normal.
…by ‘a bit more advanced’ I mean any conversation involving me and SARG-ability would carry along these lines…
> Do you know what SARG-ability is?
>> Me? Yeah, totally!
> Great! What is it so?
>>…eh….indexes?
Which isn’t totally wrong but since SARG-ability is a main part of this post, it’s best I give you a definition and an example (BONUS: a lovely video!)
So a query is SARGable if “the DBMS engine can take advantage of an index to speed up the execution of the query.”
This SARG-ability is what we are going to be searching for today because we’re going to be searching a table of 15,000,000 rows.
…why 15,000,000? Well I first wanted to populate as many rows as I could but thanks to the joys that are Cartesian products I ended up crashing my SSMS! So 15,000,000 will do us…
Now if this was a book and we had to search every single 15,000,000 pages of that book for the page with the result we want OR if we had the option to go to the back of the book, look up on the index where the the result is and go directly to that page, which do you think would be faster? Easier?
…I’m really hoping you went with the Index option…
Hence, in our example SARG-ability is good and it’s what we want to achieve today.
So with that, on to the actual post…
One of the most common things to search for in SQL Server is dates. Nice and simple and everyone has (presumably) done it.
SELECT * FROM [<my_schema>].[<my_table>] WHERE [<date_column>] = '<date>';
Fine, grand, no problem…if your table is small but remember, we’ve got a table with 15,000,000 rows. Checking every single row is just not going to cut it here.
Unfortunately that is what happened in this situation.
A requirement was given to Development to get all the rows where the date was this year, and Development were smart enough to know that there is a SQL Server function for that.
DECLARE @Year INT = 2016; SELECT [Test_Date] FROM [dbo].[DateTest] WHERE YEAR([Test_Date]) = @Year;
So they sent it onto me to approve and apply to the QA environment and I did what I have come to learn is what most DBA’s do to Developers, I said no.
Why? Here’s why?
First lets create a test table to run this against…this insert took around 2 minutes on my machine.
-- First, create our table CREATE TABLE [dbo].[DateTest] ([Date_Test_Id] INT IDENTITY(1, 1), [Test_Date] datetime2(3)); -- Populate it with 15,000,000 random rows -- from 1st Jan 1900 to 1st Jan 2017. INSERT INTO [dbo].[DateTest] ([Test_Date]) SELECT TOP (15000000) DATEADD(DAY, 0, ABS(CHECKSUM(NEWID())) % 42734) FROM [sys].[messages] AS [m1] CROSS JOIN [sys].[messages] AS [m2]; -- Create an index we can use for our tests CREATE NONCLUSTERED INDEX [nci_DateTest_Test_Date] ON [dbo].[DateTest] ([Test_Date]); -- Show the data SELECT * FROM [DateTest];
…who else knew that there was 42734 days from the 1st of Jan 1900 to the 1st of Jan 2017? I didn’t!…
So now that 1). we have our table and b). we have an index we can use, we can run the developer’s query and be SARGable right?
DECLARE @Year INT = 2016; SELECT [Test_Date] FROM [dbo].[DateTest] WHERE YEAR([Test_Date]) = @Year; GO

Nope! Table scan, ignores our Index and reads all 15M (too lazy for all the zeros) for a measely 127,782 rows! It’s not the slowest, taking around 3.960 seconds but still, we want SARGable!!!
…your row results may differ, random is random after all…
So being the kind, gentle, caring soul that I am (as well as being on my fourth coffee) I went back with a SARGable method.
DECLARE @Year INT = 2016; SELECT [Test_Date] FROM [dbo].[DateTest] WHERE [Test_Date] < DATEADD(YEAR, (@Year - 1900) + 1, 0) -- Start of Next Year AND [Test_Date] > DATEADD(YEAR, (@Year - 1900), - 1); -- End of Last Year GO

Look at that beautiful, beautiful index seek. 127,782 rows in 1.807 seconds, over twice as fast!
But as beautiful as that index seek is, it is not what the developer saw.
> That’s an ugly query, it’s going to be horrible to troubleshoot that.
And off he went.
What he came back with was pleasantly surprising and reminds me that one of the best thing about SQL Server is, that for all it’s restrictive syntax and rules, there is no 1 way to do anything.
What he came back with was the beauty of DATEFROMPARTS.
DECLARE @Year INT = 2016; SELECT [Test_Date] FROM [dbo].[DateTest] WHERE [Test_Date] BETWEEN DATEFROMPARTS(@year, 1, 1) AND DATEFROMPARTS(@year, 12, 31); GO

Boom! Index seek of 127,782 rows in 1.807 seconds.
I was happy cause it was SARG-able and he was happy as it was easier to troubleshoot.
So he asked if it could be applied to the QA environment and I did what I have come to learn is what most DBA’s do to Developers, I said no.
In case you’re wondering why, consider two things: the data type of the [Test_Date] column and this example.
SELECT * FROM [dbo].[DateTest] WHERE [Test_Date] = '2016-12-31';
378 row(s) affected.
UPDATE TOP (3) [dbo].[DateTest] SET [Test_Date] = '2016-12-31 12:34:56' WHERE [Test_Date] = '2016-12-31';
3 row(s) affected.

3 rows difference…I’ll let you figure out why.
Letting SQL Server Management Studio tell you what you’ve just run
There has been multiple times when I’ve been running part of a large query script and someone something has distracted me.
Next thing I know I look back at my screen and my results pane shows:
(2089 row(s) affected)
Now that might be fine if you’ve ran what I just ran:
SELECT TOP (2089) * FROM sys.all_objects;
but what happens when you take another look at the code and what you thought you’ve just ran is in the middle of the following
INSERT INTO [very_important_table] SELECT [id], [random_string_column], [random_int_column] FROM [user_input] as [ui] -- if it's in not in the table, then insert it WHERE NOT EXISTS ( SELECT 1 FROM [user_input] as [exists] WHERE [exists].[id] = [ui].[id] ); SELECT TOP (2089) * FROM sys.all_objects; DELETE FROM [very_important_table]; --WHERE [important_table_Id] = 1 -- commented out WHERE CLAUSE
Suddenly you’re not sure if you really ran the SELECT statement at all.
Maybe you ran the insert statement and 2089 rows were marked to never be seen again!
Or maybe that other table only had 2089 rows in it and you’ve now deleted every one!!
Now this blog post is not going to deal with fail-safe’s for preventing those scenarios because 1) you should already know how to do that, and b) if you don’t know, then maybe back away until you research it… It’s only going to deal with a nice little way you can figure out what it was that you just ran.
In SSMS, there are 4 different ways to deal with query results.
Now you may have noticed that for that list, I gave you the keyboard shortcuts for each option apart from the final one, and there’s a very important reason for that…
…I don’t actually know if it has a shortcut…
Honestly, I’m not sure if there is one (apart from declaring a variable as shown by Kendra Little).
What I do know is that where you go to set No Results to on is also where you go to set WHERE_WAS_I to on.


…check some of these other options out too, they’re pretty useful…
From here we can already see that I have that magical little checkbox “Include the query in the result set” ticked, and 3 check boxes down from that is the No Results checkbox “Discard results after execution”.
…if you want it to take affect, you’ll need to open a new Query Window…
Now seeing as I had that checkbox ticked, all I have to do is open the Messages tab in the results pane and there will be the text that you ran, your little WHERE_WAS_I.

…okay so I cheated, I ran the whole thing and only showed you part of the results pane. Sorry I’m not sorry 🙂 …
The good news is that now we know what was ran…EVERYTHING…but seeing as this is a massively contrived example…I mean who calls a table [very_important_table]…it works for what we want.
From this we can see
Like I said, it’s not a fail-safe but just a little nudge to let you know where you are. Hopefully it should help you out with knowing what it was that you just ran…even if what it tells you wasn’t what you wanted to see!
P.S. this is closest that I’ve found to a shortcut for this. If you click the Query Options button below and click the checkboxes that way it will also work but only for the session window that you are in!


Is there is any event that is a great starting off point for new bloggers than T-SQL Tuesday? It gives you everything you need, a topic, a semblance of choice, a deadline…
This month’s T-SQL Tuesday is hosted by Jens Vestergaard (b/t) and the topic is out favourite SQL Server Feature.
Now I didn’t realise that I had a favourite SQL Server feature until I had to sit down and think about it and I realised that the moment that I learned how to use CTE’s, I’ve been using them non stop. So much so that in a previous job, a developer once said he could recognize a stored procedure I had written just because it contained a CTE!
… it didn’t help that in that case he was right 🙁 …
According to Books Online, a CTE is a “temporary named result set” that is defined within the scope of a single statement. In case you are worries about the ‘single statement’ aspect of that, don’t be. With temp tables, Variables table, etc, SQL Server got you covered ;).
As this is the first blog post, I’ll keep this short and sweet. The main capacity of CTE’s that I admire is the RECURSIVE element to them.
Recursive CTE’s require only 4 aspects
With the release of the new STRING_SPLIT function in SQL Server 2016 that everyone is looking forward to, it’s probably fitting that the example of a recursive CTE that I’ll be using is to split a string. Since this post is about Recursive CTE’s I’ll be focusing on the architecture of the CTE more than what is in the script though!
So for our example, say we are given a variable sting with a list of elements in it…
DECLARE @string VARCHAR(100) = 'SELECT,INSERT,UPDATE,DELETE,EXECUTE'
…and we are tasked with splitting this string out into it’s different parts. Now there are multiple different ways that this could be accomplished (nearly all of them faster and more efficien) but we’re going the recursive CTE route!
DECLARE @string VARCHAR(100) = 'SELECT,INSERT,UPDATE,DELETE,EXECUTE' -- This value is used to split out the string : , @delimiter CHAR(1) = ','; -- Add on a final delimter to get the last element SELECT @string = @string + @delimiter; WITH delimiting_cte ( ID, original_text, remaining_text, delimited_text ) AS ( -- Anchor stmt : SELECT CAST( 1 as SMALLINT ), @string, RIGHT( @string, ( LEN( @string ) - CHARINDEX( @delimiter, @string ) ) ), --remaining_text SUBSTRING( @string, 1, CHARINDEX( @delimiter, @string ) - 1 ) -- delimited_text -- Joining Statement : UNION ALL -- Recursive stmt : remove each delimited value to put in own row... SELECT CAST( c.ID + 1 as SMALLINT ), c.original_text, RIGHT( c.remaining_text, ( LEN( remaining_text ) - CHARINDEX( @delimiter, c.remaining_text ) ) ), -- remaining_text SUBSTRING( c.remaining_text, 0, CHARINDEX( @delimiter, c.remaining_text )) -- delimited_text FROM delimiting_cte as [c] WHERE -- Terminator clause: Until no delimiter left in the [remaining_text] column... remaining_text like '%['+@delimiter+']%' ) SELECT ID, original_text, remaining_text, delimited_text FROM delimiting_cte as [c];
The anchor statement is static, it doesn’t change. You can take that query out, run it all day long and you’d get the same results. No changes here, this is what the recursive derives itself from!
-- Anchor stmt : SELECT CAST( 1 as SMALLINT ), @string, RIGHT( @string, ( LEN( @string ) - CHARINDEX( @delimiter, @string ) ) ), SUBSTRING( @string, 1, CHARINDEX( @delimiter, @string ) - 1 )
However, it has the basic limitation of a CTE in that it requires distinct column names
So we have two options, define them at the start:
WITH delimiting_cte ( ID, original_text, remaining_text, delimited_text ) AS ( SELECT ...
or define them inside the anchor statement itself:
WITH delimiting_cte AS ( SELECT [ID] = CAST(1 AS SMALLINT), [original_text] = @string...
Whatever we choose the only caveat is that each column must have a distinct column name.
Nice and simple, we need something to join the anchor and the recursive statement together:
-- Joining Statement : UNION ALL
(Ever wonder what happens if you change this to UNION? INTERSECT? EXCEPT? Go on, give it a go and find out!)
Now this is metaphorically where the magic happens. There are a couple of things here that are worth pointing out.
This is the complete opposite of the Static Statement, this will not run on it’s own! It needs the Anchor Statement to actually execute. This is because you are SELECTing from the CTE while still defining the CTE!!
I can’t think of another aspect in SQL that has this behaviour but if anyone knows, let me know!
On the same level, we call the column names themselves as well here but we don’t have to give these guys distinct column names. SQL Server is smart enough to get their position and match them up with the column name in the Anchor Statement, much like a regular UNION ALL expression.
However, like a regular UNION ALL expression, the columns in the Recursive Statement need to be the same data types as the Anchor Statement otherwise it throws a slight hissy fit errors out!
-- Recursive stmt : remove each delimited value to put in own row... SELECT CAST( c.ID + 1 as SMALLINT ), c.original_text, RIGHT( c.remaining_text, ( LEN( remaining_text ) - CHARINDEX( @delimiter, c.remaining_text ) ) ), -- remaining_text SUBSTRING( c.remaining_text, 0, CHARINDEX( @delimiter, c.remaining_text )) -- delimited_text FROM delimiting_cte as [c]
SQL server has a MAXRECURSION setting in it. Pretty smart when you think about it unless you’re a fan of Infinite Loops. Unless specified otherwise, Recursive CTE’s will stop after 100 recursions. (and no, I’m not going to tell you how to increase this limit, it’s right there in the Books Online).
However, if we want the CTE to not error out, it may be a good idea to stop it before it hits that limit so that’s why we have Terminator clauses.
WHERE -- Terminator clause: Until no delimiter left in the [remaining_text] column... remaining_text like '%['+@delimiter+']%'
Now we can specify this inside the CTE or in the statement after it but like already stated, best have this somewhere (unless you like error messages…)
And that’s the surface of recursive CTE’s, if not scratched then definitely slightly scraped.
They are so many more uses for these guys and some genius ones have already been blogged about.
Jeff Moden uses CTE’s for his Tally Table and even gives you a glimpse into his string splitter which I definitely recommend checking out.
And this is definitely my favourite SQL Server feature…so far 🙂




