
Words: 725Time to read: ~4 minutes
Continue reading “Using Multiple Delimiters to Split Strings with PowerShell”
I appear to be going for the Ronseal titles lately…
Words: 725Time to read: ~4 minutes
Continue reading “Using Multiple Delimiters to Split Strings with PowerShell”
REVOKE Permissions doesn’t work…but GRANT & DENY does…
Grant Fritchey ( b | t ), in his infinite wisdom, has created a challenge; a random blog post challenge all to do with the featured image at the top of this post:
Actually, from his blog post, his actual reason was…
for no particular reason at all or maybe because I had too much food at lunch or just because Jason Hall gave me the idea
Now to me, that is a cheeky response, which is fitting because this seems like a cheeky gif… as in it is saying “oh hey!” in response to someone asking “Who did this?!”.
So taking this into account, I’ve decided to document some cheeky behaviour with permissions in SQL Server.
Let us create a super secret table, with a super secret column containing a super secret value that only we should be able to update.
USE Pantheon; GO CREATE TABLE dbo.SuperSecretContent ( ID int IDENTITY(1, 1) ,SecretColumn varchar(50) ); GO INSERT INTO dbo.SuperSecretContent (SecretColumn) SELECT RIGHT(NEWID(), 50); GO
Yeah…I know, my super secret value is a NEWID()…I’m not sorry.
We also have a random LOGIN and USER that we didn’t create but we somehow have the create scripts for…
USE [master]; GO CREATE LOGIN [PhysicianWhom] WITH PASSWORD = 'A_Rapid_Hedgehogs_Wrench'; GO USE [Pantheon]; GO CREATE USER [PhysicianWhom] FROM LOGIN PhysicianWhom; GO
One day we check out our super secret value and we see:
SELECT SecretColumn FROM dbo.SuperSecretContent; GO


Dammit! He must have access to db_datawriter so he can update all user tables. I’ll do a quick check just to make sure!
SELECT Users.[name] AS UserName , DBRoles.[name] AS RoleName FROM sys.database_principals AS Users INNER JOIN sys.database_role_members AS RoleMembers ON Users.principal_id = RoleMembers.member_principal_id INNER JOIN sys.database_principals AS DBRoles ON DBRoles.principal_id = RoleMembers.role_principal_id WHERE Users.[name] = N'PhysicianWhom'; GO

Ha! I know how you did it now. You’re not going to be in that database role for long! If he needs update access to other tables then we can grant UPDATE permissions on those tables individually.
Let’s remove him and then refresh our table.
-- Role ALTER ROLE db_datawriter DROP MEMBER PhysicianWhom; GO TRUNCATE TABLE dbo.SuperSecretContent; GO INSERT INTO dbo.SuperSecretContent (SecretColumn) SELECT RIGHT(NEWID(), 50); GO

Time passes and we check our value again:
Arrgh!!! How? Wait, do you have UPDATE permissions on my table?
SELECT Users.[name] AS UserName , Perms.[permission_name] AS PermissionGranted , Perms.class_desc AS PermissionOn , Obj.[name] AS ObjectName , Perms.state_desc AS PermissionState FROM sys.database_principals AS Users INNER JOIN sys.database_permissions AS Perms ON Perms.grantee_principal_id = Users.principal_id INNER JOIN sys.objects AS Obj ON Obj.[object_id] = Perms.major_id WHERE Users.[name] = N'PhysicianWhom'; GO

This is no one’s fault but my own. Removing them from the db_datawriter role was a shotgun approach, I need to be more precise. So I’m going to DENY him update access to my table and then the problem will be over.
DENY UPDATE ON dbo.SuperSecretContent TO PhysicianWhom; GO TRUNCATE TABLE dbo.SuperSecretContent; GO INSERT INTO dbo.SuperSecretContent (SecretColumn) SELECT RIGHT(NEWID(), 50); GO

He can’t have updated it…right?
I mean, he doesn’t have db_datawriter permission; I’ve denied him update permission on my table. I’m safe!…right?
[It’s at this point I went and got a cup of coffee..]
But I denied him! I denied him!

No! He will not win! I am determined…but lost? In my desperation, I scour Books Online and chance upon this little nugget from BOL…
A table-level DENY does not take precedence over a column-level GRANT. This inconsistency in the permissions hierarchy has been preserved for the sake of backward compatibility. It will be removed in a future release.
…and a small ray of light shines through.
I make a quick modification to my permissions script…
SELECT Users.[name] AS UserName , Perms.[permission_name] AS PermissionGranted , Perms.class_desc AS PermissionOn , Obj.[name] AS ObjectName , Perms.state_desc AS PermissionState , ( SELECT [name] FROM sys.columns AS c WHERE c.[object_id] = Obj.[object_id] AND c.column_id = Perms.minor_id) AS ColumnPermission FROM sys.database_principals AS Users INNER JOIN sys.database_permissions AS Perms ON Perms.grantee_principal_id = Users.principal_id INNER JOIN sys.objects AS Obj ON Obj.[object_id] = Perms.major_id WHERE Users.[name] = N'PhysicianWhom'; GO

How do I fix this?
A deny is not going to work; we’ve already tried that.
Adding him to db_denydatawriter is not going to work. What happens if he needs to update other tables in our database?
But if we GRANT him access on our entire table then that will overwrite our column level GRANT. Then we can DENY him on our table and all is write…I mean right with the world!
GRANT UPDATE ON OBJECT::dbo.SuperSecretContent TO [PhysicianWhom] DENY UPDATE ON dbo.SuperSecretContent TO PhysicianWhom; GO

EXECUTE AS LOGIN = 'PhysicianWhom'; SELECT USER_NAME() AS WhoooAreYou; UPDATE dbo.SuperSecretContent SET SecretColumn = 'Are you listening to me?' WHERE 1 = 1; GO SELECT SecretColumn AS UpdatedTo FROM dbo.SuperSecretContent; GO REVERT; GO

A little present for all you “deprecated means nothing” people out there.
I’m just going to highlight a section here of relevance:
A table-level DENY does not take precedence over a column-level GRANT. This inconsistency in the permissions hierarchy has been preserved for the sake of backward compatibility. It will be removed in a future release.
I aimed to get this blog post out yesterday but when I ran this on…
Microsoft SQL Server 2016 (SP1) (KB3182545) – 13.0.4001.0 (X64)
Oct 28 2016 18:17:30
Copyright (c) Microsoft Corporation
Developer Edition (64-bit) on Windows 10 Pro 6.3 <X64> (Build 14393: )
…then my table-level DENY DID take precedence over my column-level GRANT.
When did they introduce that? Was this mentioned and I just missed it? Seriously give it a go and see for yourself!
The Good, the Bad, and the Bug-ly.
This month’s T-SQL Tuesday is brought to us by Brent Ozar ( work | personal | tweets ) and has to do with SQL Server Bugs and Enhancement requests on Microsoft Connect.
Now the reason that this is the topic of this month’s T-SQL Tuesday is nicely spelled out by the host himself:
Now, more than ever, Microsoft has started to respond to Connect requests and get ’em fixed not just in upcoming versions of SQL Server, but even in cumulative updates for existing versions.
If you’ve kept an ear to the ground and an eye out on the social media, (seriously get on Twitter if you haven’t already; with #sqlhelp and #sqlfamily, you’ll never be alone, stuck, and/or bored again), you’d realise that this is true. Microsoft has engaged more than ever with it’s audiences, from hiring a PowerShell developer to actively engaging in various Trello Channels. So much so that a twitterbot was created to keep track of Connect items closed as fixed (Closed As Fixed) by MVP Chrissy LeMaire ( blog | tweets ).
Now, I happen to have a Connect item and I’m going to link to it here. I can do this as this blog shares a commonality with Lesley Gore’s birthday party song. (It’s mine and I can cry if I want to)
Include Clustered Index when altering Indexed Views
However, this T-SQL Tuesday topic has a secondary agenda of getting these Connect items up-voted if we agreed with them. So with that in mind, and seeing how I already had a Connect item open dealing with Views, I took a look at other Connect items around Views to see what else there was and up-voted what I could.
That’s not contributing enough, I hear you say? (Yes, I’ve already heard the “you’re hearing voices” joke, and yes it is slightly funny).
Well that’s fine, because I’m going to highlight and link the Connects I found below for you guys to decide.
So go on! Pretend you’re the Emporer of Rome, a Julius/Julia CTE-aeser, determing the fate of these gladitorial Connect items. Do they get the thumbs up? Or the thumbs down?
First of all, lets see what we’re running on here…
SELECT @@VERSION

First contender: Inserting to an indexed view can fail
What would happen if I told you that, with regards to a view, sometimes inserting into the table could fail? Well that’s what this Connect item from Dave_Ballantyne found, along with the reason.
CREATE TABLE myTable
(
Id integer not null,
InView char(1) not null,
SomeData varchar(255) not null
)
GO
CREATE VIEW vwIxView
WITH SCHEMABINDING
AS
SELECT
ID,
Somedata,
LEFT(SomeData, CHARINDEX('x', SomeData) - 1) AS leftfromx
FROM
dbo.myTable
WHERE
InView ='Y'
GO
CREATE UNIQUE CLUSTERED INDEX pkvwIxView ON vwIxView(Id)
GO
Now that we have the groundwork laid out, it’s time for our insert attempt:
DECLARE @id integer, @inview char(1), @Somedata char(50) SELECT @id = 1, @inview = 'N', @Somedata = 'a' INSERT INTO myTable(Id, InView, SomeData) SELECT @id, @inview, @Somedata

He’s even gone so far as to give an explanation as to why this happens!
This is due to the compute scalar being executed prior to the filter.
Taking a look at the estimated execution plan, we can see that he’s right!

Imagine trying to troubleshoot what was causing the inserts to fail? Horrible! I can imagine tearing my hair out at that one!
I have this done as “The Good” just for the fact that, not content to just report the bug, Dave_Ballantyne even went so far as to find the possible cause. Now it’s just up to Microsoft to get to the fixing…
Next up, we have moody31415 with “Can’t create Materialized View that references same table twice”
Groundwork:
CREATE TABLE test (A int) GO CREATE VIEW vtest WITH SCHEMABINDING AS SELECT t1.A, t2.A as A2 FROM dbo.test T1 JOIN dbo.test T2 ON T1.A=T2.A GO
The problem occurs when we try to add a unique clustered index on this bad boy:
CREATE UNIQUE CLUSTERED INDEX UCL_Test on dbo.vTest (A, A2)

Now, I originally put this down as “The Bad” because I thought that the issue could be down to trying essentially index the same column twice but that’s not the case…
CREATE TABLE dbo.B (col1 tinyint, col2 tinyint) GO CREATE VIEW dbo.SecondOne WITH SCHEMABINDING AS SELECT t1.col1, t2.col2 FROM dbo.B AS t1 JOIN dbo.B AS t2 ON t1.col1 = t2.col1 GO CREATE UNIQUE CLUSTERED INDEX UCL_test ON dbo.SecondOne (col1, col2)

In the end, the reason that I have this in “The Bad” section is that I went to the documentation and read this part…
The SELECT statement in the view definition must not contain the following Transact-SQL elements: […] self-joins […]
Now it’s unknown whether this was there when this Connect item was created, but it’s there now (and I didn’t have enough time to re-plan this blog post)
In my quest through the magical lands of Connect I stumbled across this little beauty of a bug by Anatoly V. Popov that I had to mention as “The Bug-ly”.
Altering indexed view silently removes all indexes
Yes, I know it’s the same as my one but dammit if I don’t think it’s a bug! That’s why it’s getting my “The Bug-ly” title.
This leaves me with a bit of a conundrum though…Do I close mine and comment on this one to get re-opened? Or do I try and continue to push on my one?
To be honest I don’t know which option to choose but, for anyone new to SQL Server, filing a Connect Item is an exciting but nerve-wracking time.
Exciting because you’ve worked with SQL Server enough to think you know how something should be done.
However, it’s nerve-wracking because you haven’t worked with SQL Server for long enough to know if you are just whining or have an actual item to be taken seriously.
Finding this Connect item was a small little shot of validation for me. Just a little something to say “Hey, I thought this too and I’m with you”.
It’s a great thing that Microsoft have started to respond to the Connect Items again and going through them you realise how different people are using SQL Server in ways that you didn’t even think to imagine.
So check out a few, leave your comment and up-vote/down-vote as you see fit.
Just…just don’t be this guy please

When disabling sysadmin logins just ain’t enough
words: 691
Reading Time: ~3 minutes
I’m becoming more and more of a fan of Powershell the more that I interact with it. And I’m a big fan of the work that those over at dbatools are doing (seriously, check it out and also check out their Slack channel).
So when reading an article by Steve Jones (b|t) that mentions using Powershell, especially dbatools, I took immediate attention!
However, while reading the blog, what jumped out at me was the fact that dbatools copies the logins and the passwords. I think that’s epic and saves so much hassle, especially with migrations and environment creation.
But when you script out a login in SSMS, you get the following “warning comment” (and this comes straight from Microsoft) :
/* For security reasons the login is created disabled and with a random password. */
I understand why you don’t want to script out a login’s password for security reasons but disabling it…does that even do anything?
Something that I only recently learned is that, for logins with high privileges, disabling them is not enough; they must be removed.
Overkill, I hear you say?
Example, I retort!
I will admit that for my example to work, there needs to be help from a member of the securityadmin server role login. So for this example we’re going to have…
-- Create a high privilege login (HPL)
CREATE LOGIN [AllThePower]
WITH PASSWORD = '1m5trong15wear!';
ALTER SERVER ROLE sysadmin
ADD MEMBER AllThePower;
-- Disable it.
ALTER LOGIN AllThePower DISABLE;
-- Create a "compromised" login
CREATE LOGIN Enabler
WITH PASSWORD = 'AlreadyHereButCompromised';
-- Make them part of security so can grant permissions
ALTER SERVER ROLE securityadmin
ADD MEMBER Enabler;
-- Create a low privilege login (LPL)
CREATE LOGIN Copycat
WITH PASSWORD = 'NotAsStrongButDoesntMatter';
So now we have all our actors created, we need to connect to the database with all 3 accounts.
Simple as “Connect” -> “Database Engine” -> Change to SQL Auth. and put in the details above for who you want.
First things first, check who we are and who can we see?
-- Who are we?
SELECT
SUSER_NAME() AS LoginName,
USER_NAME() AS UserName;
-- Who can we see?
SELECT
*
FROM sys.server_principals;

Okay, so we can’t see it but we know that it’s there.
Let’s just cut to the chase and start “God-mode”
-- Can we get all the power ALTER SERVER ROLE sysadmin ADD MEMBER CopyCat;

Can we impersonate it?
-- Can we impersonate AllThePower
EXECUTE AS LOGIN = 'AllThePower'
SELECT
SUSER_NAME() AS LoginName,
USER_NAME() AS UserName;

Time to go to our compromised account:
Now, who are we and what can we see?
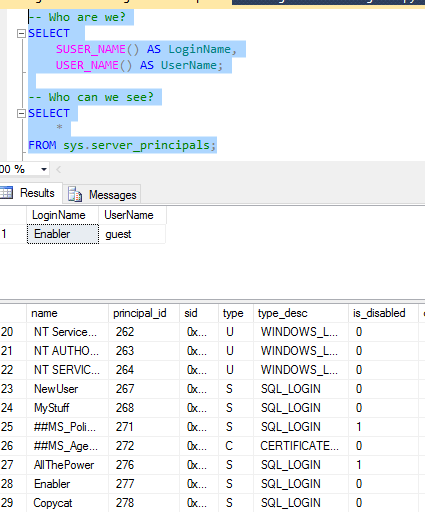
Notice that “Enabler” as part of securityadmin can see the disabled “AllThePower” login?
Great, we can see it, so let’s promote our CopyCat login!
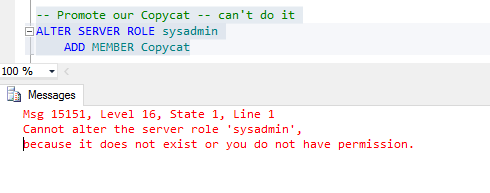
So even though we’re now a member of the securityadmin role, we still can’t promote our login!
I think you’d be safe in thinking that people would give up here, but we know from server_principals that “AllThePower” is there, even though it’s disabled!
So even though we don’t have the ability to promote our login, we do have something that we can do in our power.
GRANT IMPERSONATE.
-- Give CopyCat Grant permission GRANT IMPERSONATE ON LOGIN::AllThePower TO CopyCat;

Now can we impersonate our Disabled login?

And can we get all the power?

Finally, we’ll revert our impersonation and see if we actually are sysadmin?
-- Go back
REVERT;
SELECT
SUSER_NAME() AS LoginName,
USER_NAME() AS UserName;
-- Are we superuser?
SELECT IS_SRVROLEMEMBER('sysadmin') AS AreWeSysAdmin;

And now I can do whatever I feel like, anything at all!
I’m a fan of removing high-permission accounts that are not needed but I’ve never put into words why. Now I know why disabling is just not enough and, for me, removing them is the option.
words: 519
Reading time: ~2.5 minutes
Recently I was asked by a developer whether they could use sp_rename to change the schema of a table.
I said no but I realised that I don’t know for sure as I’ve never tried it this way.
Granted I have never needed to when we have such a descriptive command like ALTER SCHEMA.
So I tested to see if sp_rename could change the schema of a table and thought I would share my results.
Here they are:
SELECT [Schema Name] = SCHEMA_NAME([schema_id]), [Table Name] = [name] FROM sys.tables WHERE [name] = N'Alphanumeric';

Now taking a look at the documentation for “sp_rename”, turns out all we need is
So with that, it seems simple to run the following…
EXEC sp_rename @objname = N'dbo.Alphanumeric', @newname = N'deleteable.Alphanumeric', @objtype = 'OBJECT';

So now all there is left to do is check if it worked, so we run our first script again and we get???:

I repeat the above: eh…what???
Where did my table go???
Please tell me I didn’t delete the table? It’s a test system and I took a backup before starting but it’s a whole lot of hassle to recreate the table.
However, on a whim, I changed my first query to use a LIKE:

So I haven’t changed the schema? I’ve renamed it to be dbo.deletable.Alphanumeric?
Is that even query-able?
SELECT * FROM dbo.deleteable.Alphanumeric; -- Fails! SELECT * FROM [dbo].[deleteable.Alphanumeric]; -- Works!


Okay, let’s just change it back quickly and pretend it never happened:
EXEC sp_rename @objname = N'deletable.Alphanumeric', @newname = N'Alphanumeric', @objtype = 'OBJECT';

Okay, okay maybe it’s like the SELECT statement and I need to wrap it in square brackets?
EXEC sp_rename @objname = N'[deletable.Alphanumeric]', @newname = N'[Alphanumeric]', @objtype = 'OBJECT';

Maybe we’re being too specific?
EXEC sp_rename '[deleteable.Alphanumeric]', 'Alphanumeric';

A quick run of our first script to confirm?

Now, as to why that syntax works but the others don’t…I have no idea.
I will try and figure that out (fodder for another blog post 🙂 ) but I’m going to need a few more coffees before I go touch that again.
It’s a bit sad though… all that hassle for something that didn’t even work in the end?
Now, lets check out the documentation of “ALTER SCHEMA”.
Seems simple, but then so did sp_rename and that burnt me.

A quick check to see if it actually worked as I’m not swayed anymore just by a lack of warnings:

If I didn’t know the answer at the start, I definitely do now.
Can you change the schema of an object by using “sp_rename”?
Hell no.
Save yourself the hassle and just stick to ALTER SCHEMA. It’s easier, believe me.
Words: 349 Reading Time: ~1.5 minutes.
Recently I was asked to create a temporary user with SELECT permissions on a database.
So far, not a problem. Taking advantage of the pre-defined roles in SQL Server, I just add this new user to the pre-defined role [db_datareader], which grants SELECT permissions to all tables and views in a database.
Why would I grant SELECT permissions this way and not manually choose the tables and views that this user could connect to?
Why grant SELECT on tables individually when I can grant on all tables in 1 fell swoop?
In the same vein, hypothetically speaking, if I was asked to grant SELECT permissions on 96 out of 100 tables, I would GRANT SELECT on all of them and then DENY SELECT on the 4 required as long as no column-level GRANTs have been given on those tables.
A recent notion that came to me was that one of the roles of a DBA is to gather knowledge, but to a level that promotes efficiency.
Sure, we know how to grant permissions, but we should also know the pitfalls, such as “deny beats grant unless the grant is on the column level” or “there are some combinations of permissions that allow more than intended“.
Knowing these caveats allows us to say when options can be automated or where rules need to be added to check for different statuses.
This will allow us to move on to the next aspect that needs a DBA’s eye and gentle guiding touch…or 2 cups of coffee and a full throttling !
Could be my shortest blog post so far…
Kalen Delaney ( blog | twitter ) has an excellent blog post about Windows Fast Startup and, while I’m not going to repeat what she has said here because, like I already mentioned, it’s an excellent post and I encourage you to read it ( and maybe give her a lil’ subscribe 😉 ), what I will mention is that I encountered this feature with my new laptop and had it interfering with my SQL Server testing (again read her post as to possible causes why).
Using Powershell for documenting Replication had me wondering if there was a way I could get around this using Powershell. So while this is another post that is not about SQL Server, it is about Powershell.
Hey, at least I’m consistent in my consistencies.
A quick lmgtfu, brought me to the following page and command:
shutdown /s
Which pops open a window saying the computer will shutdown and, after a delay, that’s what it does.
At this stage I’ve read enough documentation to know that
shutdown /s
doesn’t follow the standard Verb-Noun convention of Powershell and that delay was slightly annoying.
Plus, everyone raves about the Get-Help commandlet so I figured I would try that.
Get-Help *shutdown*
Gave me a list of commands and one of them seemed to fit what I wanted.
Get-Help Stop-Computer;

3 things here.
So you might already know, but I didn’t know, until I learned it, of course.
I didn’t know, but found a work-around so didn’t learn it.
I’d advise you to follow Kalen’s approach (as I’m going to try from now on) but, hey, at least you now know mine.
I am pretty sure that if I was a fish, I would not survive long enough to grow old as I would fall for the first piece of bait hanging from a lovely, shiny thing that I could see.
The only defence that I have is that, as I’m still a Junior DBA, I can make these mistakes as long as
a). they are not extremely serious (no dropping production databases for this guy!), and
b). I’m expected to learn from them and not repeat them!
And like most things, it started innocently enough. A simple support ticket coming in with the following error message.
Msg 229, Level 14, State 5, Line 65
The SELECT permission was denied on the object ‘Removable’, database ‘LocalTesting’, schema ‘Superflous’.
I saw this error message and immediately thought to myself
AH! No problems, they just need SELECT permissions on that object. 2 second job.
And seeing as the ticket was nice enough to provide the login and user that was receiving the error message (we’ll say it was a user called “NewUser”), I could join that with the error message and grant permissions.
GRANT SELECT ON OBJECT::Superflous.Removable TO NewUser;
Following this was a quick test to impersonate myself as the user and see if it works;
-- Test 01. EXECUTE AS USER = 'NewUser'; SELECT USER_NAME(), SUSER_SNAME(); SELECT * FROM dbo.GenericView;

As far as I was aware, I was happy it worked; the user, once notified, was happy it worked and I went on my merry way to grab some celebratory coffee.
Until on the way back I bumped into my Senior DBA and told him proudly what I had done…
The following is a simplified reproduction of that conversation…
>Is that a new View?
> No…
>> Is that a new User?
> No…although it’s called New.
>> Could they SELECT from that View before?
> Yeah, as far as I know.
>> Alright, so did anything change before the call?
> eh…I didn’t check
>> Okay, from now on: Check.
It was at that stage that we started getting other tickets in from other users with the same error message. So rather than fixing the underlying problem, I had fixed a symptom for a single user.
The symptom was the User not having permission to select, but the underlying problem was that the View had changed.
At this stage I was still confused as it’s a view, what does it matter if the query creating it has changed, how could this have broken permissions?
Again, jumping the gun, I didn’t check…

Our problem view has two different schemas and when we check the ownership of the two different schemas, we get the following:
-- Who owns what?
SELECT dp.name AS Owner, s.*
FROM sys.schemas AS s
JOIN sys.database_principals AS dp ON s.principal_id = dp.principal_id
WHERE s.name in ('dbo', 'Superflous');

Technically, the answer is Ownership Chains.
Originally, our Superflous.Removable table was in a different database on it’s dbo schema where the owner of the view (dbo) had permissions to select from.
Since the owner of the view (OV) had permissions on this schema and the OV gave select permissions on the view to the user (NU), the NU inherited the OV’s permissions.
dbo.Foo , saw that it was owned by OV and so didn’t need to check permissions.Now we had recently done a change to have the information from the other database brought over to our database via Replication.
This meant a re-write of our View using the new table and schema with it’s new owner. This new schema that our NU or the OV did not have permissions for.
What this meant was the same procedure was followed by the SQL Server engine with the only difference being that, instead of going across to the other database, it went to our new schema Superflous.Removable . It saw the OV did not have access permissions, so it denied access permissions for our NU.
So basically, when NewUser went to select from our view, they hit the new schema, SQL Server realised it needed to check their permissions and, when none were found, access was denied.
All I had done by jumping the gun and fixing the symptom was made it so that when SQL Server traversed down the ownership chain for the view and came to the new schema, it checked permissions, found the SELECT permission for only this user and continued on.
This was the reason that the view worked for the user but no one else!
This MyStuff database principal should not be the owner of our Removable table, in fact the Superflous schema should not even exist, so it was a simple matter of transferring ownership to dbo.
ALTER AUTHORIZATION ON SCHEMA::Superflous TO dbo;
Now all the users, who have read access on the dbo schema, are able to use this view with no further hassles.
Problem solved! Right?
All the above is what I did.
Trying to fix the permission error, I granted SELECT permission.
Trying to fix the ownership chain, I transferred ownership.
Mainly in trying to fix the problem, I continually jumped the gun.
Which is why I am still a Junior DBA.
What my Senior DBA did was fix the replication script so the new schema wouldn’t get created in the first place, and the table would get created in dbo.
Which is why he’s my Senior DBA.
Jumping the gun isn’t going to give you a head start. It is just going to delay you. Knowing the problems, as well as knowing the solutions, is the answer.
I’m learning the problems…I’ll have the solutions soon, and I aim to share them too.
Correcting an incorrect assumption helped me learn about Query Optimizer shortcuts.
A couple of weeks ago I talked about Best Practices and how it was important to understand why that something was best practice.
Well another aspect to take from that post was the importance of knowing; if you do not know something, then it is important for you to learn it.
That being said something that I did not know, but recently learned, was that there is nothing stopping a Primary Key from also being a Foreign Key.
there is nothing stopping a Primary Key from also being a Foreign Key
When you think about it, this lack of knowledge came from incorrect assumptions. You read Primary KEY and Foreign KEY and you think to yourself, well they are both keys aren’t they? Same thing.
That is the trap that I fell down and the trap is not knowing and making invalid assumptions. So let’s hopefully help you with knowing what the differences between them are.
First let’s create our tables:
-- Create our Foo and Bar table. IF OBJECT_ID(N'dbo.Bar', N'U') IS NOT NULL DROP TABLE dbo.Bar; GO IF OBJECT_ID(N'dbo.Foo', N'U') IS NOT NULL DROP TABLE dbo.Foo; GO CREATE TABLE dbo.Foo ( FooID int IDENTITY(1, 1) NOT NULL CONSTRAINT [PK_dbo_Foo] PRIMARY KEY CLUSTERED, FooValue char(8) ); GO CREATE TABLE dbo.Bar ( BarID int CONSTRAINT [PK_dbo_Bar] PRIMARY KEY CLUSTERED, BarValue char(8), CONSTRAINT [FK_dbo_Bar_dbo_Foo] FOREIGN KEY (BarID) REFERENCES dbo.Foo (FooID) ); GO -- Declare our holding table. DECLARE @FooIDs TABLE (FooID int); -- Insert into Foo. INSERT INTO dbo.Foo (FooValue) -- Gather the new ID's from foo. OUTPUT inserted.FooID INTO @FooIDs (FooID) SELECT LEFT(NEWID(), 8) FROM sys.all_objects; -- Insert Foo's ID into the Bar table. INSERT INTO dbo.Bar (BarID, BarValue) SELECT FooID, RIGHT(NEWID(), 8) FROM @FooIDs; -- Select our tables. SELECT * FROM dbo.Foo; SELECT * FROM dbo.Bar; GO

a column or combination of columns that contain values that uniquely identify each row in the table
A Primary key is a column or combination of columns that contain values that uniquely identify each row in the table.
That’s it; it just has to uniquely identify the row.
…btw you are going to hear the word “unique” a lot with regard to Primary keys…
Now there are other types of keys that can do the same (Surrogate Keys, Composite Keys, Unique Keys, Alternate Keys, etc) but these are outside the scope of this post.
So if we attempt to insert another record into our Primary Key column/column combo that violates this unique, identifying property, we’re going to have a bad time.

We have to use IDENTITY_INSERT syntax because I’ve created the tables using IDENTITY and, if we were to insert a record into the identity column without turning IDENITY_INSERT on first, then another error pops up before the PK violation error that we want.
However, if we were to create our table without specifying the Primary Key constraint then the above insert would work and you would have duplicate entries populating your table, silently and deadly.
a column or combination of columns that is used to establish and enforce a link between the data in two tables to control the data that can be stored in the foreign key table
A Foreign key is a column or combination of columns that is used to establish and enforce a link between the data in two tables to control the data that can be stored in the foreign key table.
That’s it; it just has to establish and enforce a link between data.
If we try to violate this link, SQL Server will throw a different error and not let us.

Yet if we were to create our table without specifying our Foreign key, then there would be no real link between our tables. So if our business depends on a record not being in Bar without being in Foo and we don’t have a constraint specified to that extent…
Unfortunately, I’m hard pressed to think of a way you can ensure this.
In fact, I don’t even like the above definition for Foreign keys as it states that two tables are necessary for a Foreign key constraint when only one is needed:
IF OBJECT_ID(N'dbo.HR', N'U') IS NOT NULL
DROP TABLE dbo.HR;
GO
CREATE TABLE dbo.HR
(
EmployeeID int
CONSTRAINT [PK_dbo_HR] PRIMARY KEY CLUSTERED,
FirstName varchar(20) NOT NULL,
SurName varchar(20) NOT NULL,
ManagerID int NULL
CONSTRAINT [FK_EmployeeID_Manager_ID] FOREIGN KEY
REFERENCES dbo.HR (EmployeeID)
);
GO
-- Check for foreign key
SELECT * FROM sys.foreign_keys WHERE [parent_object_id] = OBJECT_ID('dbo.HR');
GO
-- Check for primary key
SELECT * FROM sys.key_constraints WHERE [parent_object_id] = OBJECT_ID('dbo.HR');
GO
-- Check for everything.
EXEC sp_helpconstraint'dbo.HR';
GO

If you check the two definitions for Primary key and Foreign key you’ll see that, even though they are both called keys, they serve two different purposes; namely identifying rows and enforcing links.
And those two purposes are not mutually exclusive!
A column/column combo that identifies a row can also be used to enforce a link back to another table (or itself, as shown above with Foreign keys).
The assumption, that if you were one then you couldn’t be the other, was incorrect. If your business rules call for it, don’t let a column being one type of key stop it from being the other.
You may be thinking that this is a lot of hassle and that’s not an unfair thought.
Why not just not declare any key constraints and let the data fall as they may?
I will admit that is a fair bit of effort to constantly define and declare the different key constraints when creating tables, especially as Developers are focused on efficiency, but it is worth it!
Now, while the following appears to hold true for any foreign key constraint (I haven’t finished testing yet), I found these while testing the above so I’m going to include them here.
SQL Server loves primary key and foreign key constraints.
A primary key gets a unique index created on it to enforce that it is unique and, since it has an index placed upon it, it can be used to speed up query selection.
A foreign key is special though as it forces a constraint and the query optimiser can use these constraints to take certain shortcuts 🙂
-- Join our tables SELECT F.* FROM dbo.Foo AS [F] JOIN dbo.Bar AS [B] ON F.FooID = B.BarID; SELECT B.* FROM dbo.Foo AS [F] JOIN dbo.Bar AS [B] ON F.FooID = B.BarID;

Thanks to our constraint the QO knows that if something were to exist in Bar, it must be in Foo and, since we are not selecting or ordering anything from Foo, it straight up ignores it.
Less reads, less IO; in general all around better performance.
Does this work with other joins though?
Like above, with for something to exist in Bar it must exist in Foo, see if you can figure out why the QO figures it is safe to ignore some joins.
-- L.Join SELECT F.* FROM dbo.Foo AS [F] LEFT JOIN dbo.Bar AS [B] ON F.FooID = B.BarID; SELECT B.* FROM dbo.Foo AS [F] LEFT JOIN dbo.Bar AS [B] ON F.FooID = B.BarID;

-- R.Join. SELECT F.* FROM dbo.Foo AS [F] RIGHT JOIN dbo.Bar AS [B] ON F.FooID = B.BarID; SELECT B.* FROM dbo.Foo AS [F] RIGHT JOIN dbo.Bar AS [B] ON F.FooID = B.BarID;

-- F.Join SELECT F.* FROM dbo.Foo AS [F] FULL OUTER JOIN dbo.Bar AS [B] ON F.FooID = B.BarID; SELECT B.* FROM dbo.Foo AS [F] FULL OUTER JOIN dbo.Bar AS [B] ON F.FooID = B.BarID;

The “SET operators” (UNION, UNION ALL, INTERSECT, EXCEPT) act a bit differently.
I’ll let you take a look at them yourself though.
There is a lot that I have yet to learn about SQL Server, in fact that is the main reason that I created this blog; so I could read back on these posts sometime in the future and smile at my ignorance.
Hopefully the main aspect that I take from this post though is that it is okay not to know something as long as you have the desire and the initiative to learn.
Oh, and a Primary Key can be a Foreigh Key too. 🙂
Making it clear to anyone reading this but this post is about SQL Server even though I start off talking a bit about PostgreSQL.
…I know, weird right?…
I have a PostgreSQL instance on my home laptop that I haven’t used yet.
I intend to start using it soon as a sort of hobby as I feel that there are things to be learned about databases from it. Like comparing features available to PostgreSQL that are not in SQL Server and vice-versa or the different ways the same tasks are accomplished in both platforms.
However SQL Server is the platform used in my work, I still have so much to learn with it (especially with 2016 coming out!!!), and I just find it so damn interesting so I haven’t touched PostgreSQL yet.
All that being said, I have signed up to few newsletters from PostgreSQL (General, Novice, etc) and they are fascinating.
Unfamiliar words like pglogical and rsync are combined with known words like publisher and subscriber and the community itself is so vast and supportive that it rivals the #SQLFamily (from what I’ve seen and yes. I am being biased to SQL Server 🙂 ).
One of those newsletters was regarding a problem a user was having with creating databases.
When he would create a new database it was not empty as he expected but was filled with user tables, logins, etc.
What was going on?
The explanation was pretty much what you would expect, just called by a different name.
He had basically written to his Model database (called template1 in PostgreSQL) sometime ago without realising it.
PostgreSQL has the following syntax with creating databases:
CREATE DATABASE DatabaseName WITH TEMPLATE TemplateName
The new database settings are created from whatever template is specified using the WITH TEMPLATE syntax (defaults to template1 apparently).
This works the same as SQL Server, the new databases inheriting the settings from the Model system database, but in our case it is implicit. There is no call for WITH TEMPLATE Model.
This is perfectly valid syntax.
CREATE DATABASE DatabaseName
The only difference that I can tell at the moment is that PostgreSQL can have multiple different templates while SQL Server has just one; Model.
Is this restriction on database templates a good thing or a limitation? Personally I go with the former but you may feel differently.
…Multiple Models?…
This brought me back to the system databases and there was something that I realised.
A lot of new users, and I was included in this list not too long ago, do not think about the system databases.
I’m not sure I can fault them as well as it’s probably not a priority. There is so much to learn with regard to DDL statements, DML statements, Deadlocking, General T-SQL, etc, that the system databases are just a little folder under Databases that does not get opened.

However, and I can’t stress these enough, these are important!
And that is just scratching the surface!
Take care of these databases, do not limit yourself to looking after just the user databases.
They are not the only databases that need to be backed-up and they are not the only databases that can experience corruption.
I’m hoping that you believe me with this but, unfortunately, the best lessons are learned.
You should have a destructive sandbox SQL Server, (NOT PRODUCTION!!!), hopefully a little laptop at home to call your own; something that nooby else would mind you destroying basically.
Choose a system database, anyone will do; delete that database, drop it, whatever you want just make it unavailable and see how far you can get using SQL Server.
…Hell isn’t it?…
Now imagine that happened unexpectantly and unwanted on a Monday morning because you weren’t taking care of your system databases.
Take care of your System Databases.





