
Words: 854
Time to read: ~ 4.5 minutes
It’s only since I’ve started delving into PowerShell that I’ve started to use Regular Expressions (Regex).
Most of you probably don’t see an issue with this since you’ve encountered Regex before and know what it’s like.
For those that don’t, Google/Bing “xkcd 99 problems regex” to find out the gist of what people feel about it.
For those of the uniquely SQL Server persuasion, this may not even be a big deal.
So what? SQL Server doesn’t even have Regex. Why are you talking about this?
They
SSMS and Azure Data Studio
As I’m sure many of you have before, I recently received some SQL code that involved xml stored as nvarchar and some funky use of SUBSTRING() and PATINDEX() functions to get information out of it. e.g.
| DECLARE @XmlStoredAsNvarchar nvarchar(4000) = ' | |
| <EventContext> | |
| <eventType>Save Test Data</eventType> | |
| <discipline>Operations</discipline> | |
| <documentNumber>1.2.3.4</documentNumber> | |
| <documentVersion>1.0</documentVersion> | |
| <sectionNumber>1.2.1.1</sectionNumber> | |
| <sectionName>Test section: XML Test</sectionName> | |
| <tableIdentifier>1</tableIdentifier> | |
| <objectType>Object</objectType> | |
| <objectTag>1.2.3.4</objectTag> | |
| <rowIndex>10</rowIndex> | |
| <testColumns> | |
| <testColumn Index="3" Type="Choice List"> | |
| <columnName>Pass / Fail</columnName> | |
| <oldValue /> | |
| <newValue>Pass</newValue> | |
| </testColumn> | |
| <testColumn Index="4" Type="Test Value"> | |
| <columnName>Bug #</columnName> | |
| <oldValue> </oldValue> | |
| <newValue> N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="5" Type="Attachment"> | |
| <columnName>Attachment</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="6" Type="Issue"> | |
| <columnName>Deviation #</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| </testColumns> | |
| <operatingMode>N/A</operatingMode> | |
| </EventContext>'; |
Write that Funky SQL…
This is a contrived example but I was given a script that got the “Discipline”, “DocumentVersion”, “DocumentNumber”, “SectionNumber”, and “SectionName” out of the above.
| DECLARE @XmlStoredAsNvarchar nvarchar(4000) = ' | |
| <EventContext> | |
| <eventType>Save Test Data</eventType> | |
| <discipline>Operations</discipline> | |
| <documentNumber>1.2.3.4</documentNumber> | |
| <documentVersion>1.0</documentVersion> | |
| <sectionNumber>1.2.1.1</sectionNumber> | |
| <sectionName>Test section: XML Test</sectionName> | |
| <tableIdentifier>1</tableIdentifier> | |
| <objectType>Object</objectType> | |
| <objectTag>1.2.3.4</objectTag> | |
| <rowIndex>10</rowIndex> | |
| <testColumns> | |
| <testColumn Index="3" Type="Choice List"> | |
| <columnName>Pass / Fail</columnName> | |
| <oldValue /> | |
| <newValue>Pass</newValue> | |
| </testColumn> | |
| <testColumn Index="4" Type="Test Value"> | |
| <columnName>Bug #</columnName> | |
| <oldValue> </oldValue> | |
| <newValue> N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="5" Type="Attachment"> | |
| <columnName>Attachment</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="6" Type="Issue"> | |
| <columnName>Deviation #</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| </testColumns> | |
| <operatingMode>N/A</operatingMode> | |
| </EventContext>'; | |
| SELECT | |
| *, | |
| SUBSTRING(X.DataColumn,PATINDEX('%<discipline>%',X.DataColumn)+12,PATINDEX('%</discipline>%',X.DataColumn)-PATINDEX('%<discipline>%',X.DataColumn)-12) AS Discipline, | |
| SUBSTRING(X.DataColumn,PATINDEX('%<DocumentVersion>%',X.DataColumn)+17,PATINDEX('%</DocumentVersion>%',X.DataColumn)-PATINDEX('%<DocumentVersion>%',X.DataColumn)-17) AS DocumentVersion, | |
| SUBSTRING(X.DataColumn,PATINDEX('%<DocumentNumber>%',X.DataColumn)+16,PATINDEX('%</DocumentNumber>%',X.DataColumn)-PATINDEX('%<DocumentNumber>%',X.DataColumn)-16) AS DocumentNumber, | |
| SUBSTRING(X.DataColumn,PATINDEX('%<SectionNumber>%',X.DataColumn)+15,PATINDEX('%</SectionNumber>%',X.DataColumn)-PATINDEX('%<SectionNumber>%',X.DataColumn)-15) AS SectionNumber, | |
| SUBSTRING(X.DataColumn,PATINDEX('%<SectionName>%',X.DataColumn)+13,PATINDEX('%</SectionName>%',X.DataColumn)-PATINDEX('%<SectionName>%',X.DataColumn)-13) AS SectionName | |
| FROM ( | |
| SELECT @XmlStoredAsNvarchar AS DataColumn | |
| ) AS X (DataColumn); |
And while it works, I hate that formatting. Everything is all squashed and shoved together.
No, thanks. Let’s see if we can make this more presentable.
Manually

This is … okay. It gets old fast though and is very, very manual. It’s okay when everything lines up, like in the first part of the above gif, and we can use the “Ctrl + Alt & Mouse” trick but when they don’t line up, like in the second part, we have to do format each individual part.
Regex
There is an option in SSMS and Azure Data Studio when you hit “Ctrl + F” (Find) or “Ctrl + H” (Find and Replace) where you have the option to use Regex.

You can place regex in the “Find” box and it will use that for searching.
Let’s break the script I was given down into the formats I like:
- I like spaces before and after brackets
- So I need to find spaces
- I like spaces after commas,
- So I need to find commas
- I like spaces before and after plus signs, and
- So I need to find plus signs “+”
- I like spaces before and after minus signs.
- So I need to find minus signs “-“
- I like
nvarchardata types to have the N” before the single quotes.- So I need to find single quotes “‘”
Let’s turn that into Regex
Straight away, we hit a problem. Regex has the idea of “capturing groups” and the way to specify which is captured into a group is by wrapping things in brackets.
This means that if we are searching for brackets, we’ll need to escape them, which is nearly the same as escaping characters in SQL.
WHERE Name LIKE '\_underscore' ESCAPE '\';The difference between SQL escape and Regex escape is that, in SQL, you can choose any character to be the escape character while, in Regex, the backslash “\” character is used.
As for Groups, I’ll show you later more about them and what you can do with them.
- \(

- ,
- \+

- –
- ‘
Now that we have all that converted, we can put them into our search and add what we need to format them.

I added an extra search for double spaces to be replaced with single spaces since I kept replacing with a space before characters and a space after characters and that created double spaces! In the end, we are left with something more readable.

Regex and Groups
I told you earlier I’d show you more about Groups, especially what you can do with them.
Let’s take the example of changing the above example to use xQuery.
I’ve cheated a bit and created the OUTER APPLYs for the different nodes and created the XQuery for the Discipline record.
| DECLARE @XmlStoredAsNvarchar nvarchar(4000) = ' | |
| <EventContext> | |
| <eventType>Save Test Data</eventType> | |
| <discipline>Operations</discipline> | |
| <documentNumber>1.2.3.4</documentNumber> | |
| <documentVersion>1.0</documentVersion> | |
| <sectionNumber>1.2.1.1</sectionNumber> | |
| <sectionName>Test section: XML Test</sectionName> | |
| <tableIdentifier>1</tableIdentifier> | |
| <objectType>Object</objectType> | |
| <objectTag>1.2.3.4</objectTag> | |
| <rowIndex>10</rowIndex> | |
| <testColumns> | |
| <testColumn Index="3" Type="Choice List"> | |
| <columnName>Pass / Fail</columnName> | |
| <oldValue /> | |
| <newValue>Pass</newValue> | |
| </testColumn> | |
| <testColumn Index="4" Type="Test Value"> | |
| <columnName>Bug #</columnName> | |
| <oldValue> </oldValue> | |
| <newValue> N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="5" Type="Attachment"> | |
| <columnName>Attachment</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="6" Type="Issue"> | |
| <columnName>Deviation #</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| </testColumns> | |
| <operatingMode>N/A</operatingMode> | |
| </EventContext>'; | |
| SELECT | |
| EventContexts.EventContext.value( '.', 'nvarchar(4000)' ) AS EverythingAndAll, | |
| Disciplines.Discipline.value( '.', 'nvarchar(255)' ) AS Discipline, | |
| NULL AS DocumentVersion, | |
| NULL AS DocumentNumber, | |
| NULL AS SectionNumber, | |
| NULL AS SectionName | |
| FROM ( | |
| SELECT | |
| @XmlStoredAsNvarchar AS EverythingAndAll, | |
| CAST(@XmlStoredAsNvarchar AS XML) AS DataColumn | |
| ) AS InnerData | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext') AS EventContexts ( EventContext ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/discipline') AS Disciplines ( Discipline ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/documentVersion') AS DocumentVersions ( DocumentVersion ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/documentNumber') AS DocumentNumbers ( DocumentNumber ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/sectionNumber') AS SectionNumbers ( SectionNumber ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/sectionName') AS SectionNames ( SectionName ) |
Now we can use Regex and groups to change all those NULL AS ColumnName to valid syntax
Regex time
We need the following regex
- NULL AS (\w+)
What I’m searching for here is
- The exact letters “NULL AS “
- One or more “word” letters, here it means everything up to the comma or a newline, and
- I’ve put that “word” regex in brackets so it’s our “capture group”
All together, this just finds the rows NULL AS DocumentVersion,
...
NULL AS SectionName
Since we have a capture group, we can use that what is in that group, by specifying $1, so
| $1s.$1.value(‘.’, ‘nvarchar(255)’) AS $1 | Returns |
| NULL AS DocumentVersion | DocumentVersions.DocumentVersion.value(‘.’,’nvarchar(255)’) AS DocumentVersion |
| NULL AS SectionName | SectionNames.SectionName.value(‘.’, ‘nvarchar(255)’) AS SectionName |
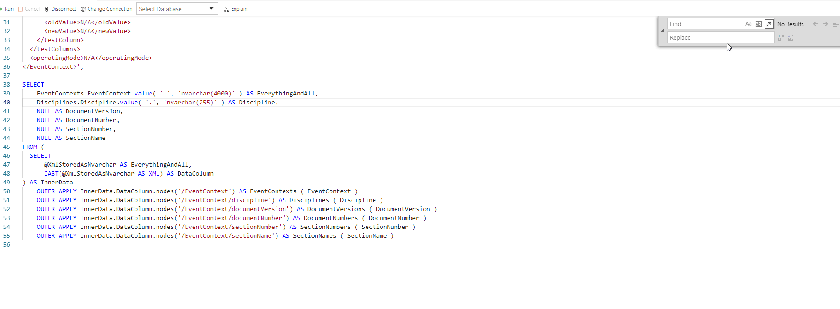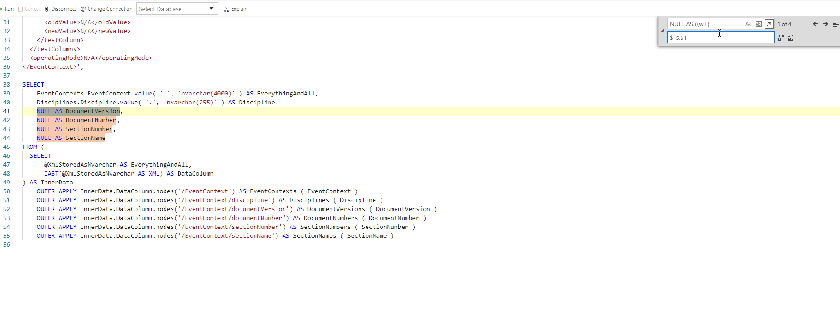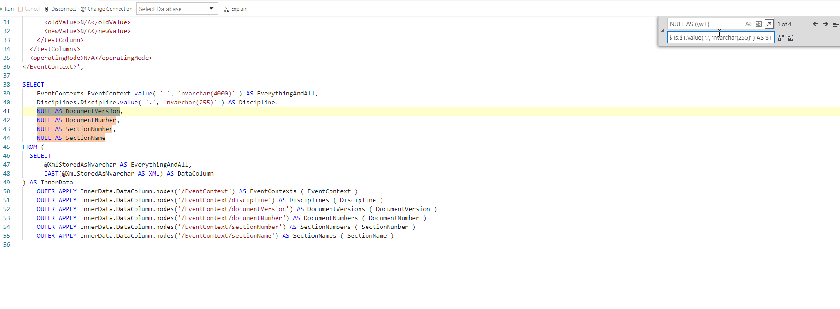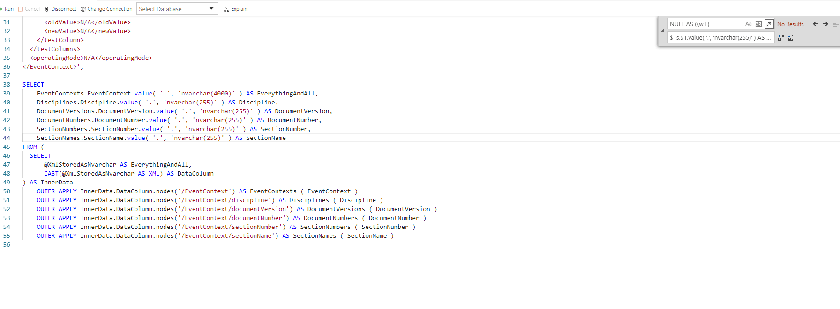
Since we only have 1 capture group we have access to $1 but if we have multiple capture groups, then we have access to multiple $1, $2, $3…
And we have a fully functioning XQuery using Regex in SQL Server.
| DECLARE @XmlStoredAsNvarchar nvarchar(4000) = ' | |
| <EventContext> | |
| <eventType>Save Test Data</eventType> | |
| <discipline>Operations</discipline> | |
| <documentNumber>1.2.3.4</documentNumber> | |
| <documentVersion>1.0</documentVersion> | |
| <sectionNumber>1.2.1.1</sectionNumber> | |
| <sectionName>Test section: XML Test</sectionName> | |
| <tableIdentifier>1</tableIdentifier> | |
| <objectType>Object</objectType> | |
| <objectTag>1.2.3.4</objectTag> | |
| <rowIndex>10</rowIndex> | |
| <testColumns> | |
| <testColumn Index="3" Type="Choice List"> | |
| <columnName>Pass / Fail</columnName> | |
| <oldValue /> | |
| <newValue>Pass</newValue> | |
| </testColumn> | |
| <testColumn Index="4" Type="Test Value"> | |
| <columnName>Bug #</columnName> | |
| <oldValue> </oldValue> | |
| <newValue> N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="5" Type="Attachment"> | |
| <columnName>Attachment</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| <testColumn Index="6" Type="Issue"> | |
| <columnName>Deviation #</columnName> | |
| <oldValue>N/A</oldValue> | |
| <newValue>N/A</newValue> | |
| </testColumn> | |
| </testColumns> | |
| <operatingMode>N/A</operatingMode> | |
| </EventContext>'; | |
| SELECT | |
| EventContexts.EventContext.value( '.', 'nvarchar(4000)' ) AS EverythingAndAll, | |
| Disciplines.Discipline.value( '.', 'nvarchar(255)' ) AS Discipline, | |
| DocumentVersions.DocumentVersion.value( '.', 'nvarchar(255)' ) AS DocumentVersion, | |
| DocumentNumbers.DocumentNumber.value( '.', 'nvarchar(255)' ) AS DocumentNumber, | |
| SectionNumbers.SectionNumber.value( '.', 'nvarchar(255)' ) AS SectionNumber, | |
| SectionNames.SectionName.value( '.', 'nvarchar(255)' ) AS SectionName | |
| FROM ( | |
| SELECT | |
| @XmlStoredAsNvarchar AS EverythingAndAll, | |
| CAST(@XmlStoredAsNvarchar AS XML) AS DataColumn | |
| ) AS InnerData | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext') AS EventContexts ( EventContext ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/discipline') AS Disciplines ( Discipline ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/documentVersion') AS DocumentVersions ( DocumentVersion ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/documentNumber') AS DocumentNumbers ( DocumentNumber ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/sectionNumber') AS SectionNumbers ( SectionNumber ) | |
| OUTER APPLY InnerData.DataColumn.nodes('/EventContext/sectionName') AS SectionNames ( SectionName ) |
$
There’s always a case of cross pollination learning when you look into different technologies.
I’m happy to add another tool to my belt but at the same time, I’m happy that it’s only available in SSMS & Azure Data Studio and not the SQL Server engine.
If you need standard formatting on queries, and I assure you that you do, consider getting a tool that will do a standard formatting for you.
Regex is a tool, just like any other. Add it to your belt but know when you can and should not use it.
One thought on “Regex and SQL Server: A Poor Man’s Quick Formatter.”